Einführung
Die Poisson-Regression wird zur Vorhersage einer abhängigen Variable verwendet, die aus „Zähldaten“ besteht, wenn eine oder mehrere unabhängige Variablen vorliegen. Die Variable, die wir vorhersagen wollen, wird als abhängige Variable (oder manchmal auch als Antwort-, Ergebnis-, Ziel- oder Kriteriumsvariable) bezeichnet. Die Variablen, die wir zur Vorhersage des Wertes der abhängigen Variablen verwenden, werden als unabhängige Variablen bezeichnet (oder manchmal auch als Vorhersage-, Erklärungs- oder Regressionsvariablen). Im Folgenden werden einige Beispiele für die Verwendung der Poisson-Regression beschrieben:
- Beispiel Nr. 1: Man könnte die Poisson-Regression verwenden, um die Anzahl der Schüler zu untersuchen, die von Schulen in Washington in den Vereinigten Staaten suspendiert werden, und zwar auf der Grundlage von Prädiktoren wie Geschlecht (Mädchen und Jungen), Rasse (Weiße, Schwarze, Hispanoamerikaner, Asiaten/Pacific Islander und Indianer/Alaska Native), Sprache (Englisch ist ihre erste Sprache, Englisch ist nicht ihre erste Sprache) und Behinderungsstatus (behindert und nicht behindert). Hier ist die „Anzahl der Aussetzungen“ die abhängige Variable, während „Geschlecht“, „Rasse“, „Sprache“ und „Behindertenstatus“ allesamt nominale unabhängige Variablen sind.
- Beispiel #2: Man könnte eine Poisson-Regression verwenden, um zu untersuchen, wie oft Menschen in Australien in einem Zeitraum von fünf Jahren mit der Rückzahlung ihrer Kreditkarten in Verzug geraten, und zwar auf der Grundlage von Prädiktoren wie Beschäftigungsstatus (angestellt, arbeitslos), Jahresgehalt (in australischen Dollar), Alter (in Jahren), Geschlecht (männlich und weiblich) und Arbeitslosenquote im Land (% Arbeitslose). Hier ist die „Anzahl der Kreditkartenrückzahlungen“ die abhängige Variable, während „Beschäftigungsstatus“ und „Geschlecht“ nominale unabhängige Variablen sind und „Jahresgehalt“, „Alter“ und „Arbeitslosenquote im Land“ kontinuierliche unabhängige Variablen sind.
- Beispiel Nr. 3: Man könnte eine Poisson-Regression verwenden, um die Anzahl der Personen zu untersuchen, die vor einem in der Warteschlange in der Notaufnahme eines Krankenhauses stehen, und zwar auf der Grundlage von Prädiktoren wie der Art der Ankunft in der Notaufnahme (Krankenwagen oder Selbstabfertigung), der bei der Triage ermittelten Schwere der Verletzung (leicht, mittelschwer, schwer), der Tageszeit und des Wochentags. Hier ist die „Anzahl der Personen vor Ihnen in der Warteschlange“ die abhängige Variable, während die „Art der Ankunft“ eine nominale unabhängige Variable, die „bewertete Verletzungsschwere“ eine ordinale unabhängige Variable und die „Tageszeit“ und der „Wochentag“ kontinuierliche unabhängige Variablen sind.
- Beispiel Nr. 4: Man könnte eine Poisson-Regression verwenden, um die Anzahl der Studenten zu untersuchen, die in einem MBA-Programm eine Note der 1. Klasse erhalten, und zwar auf der Grundlage von Prädiktoren wie den Arten von Wahlfächern, die sie gewählt haben (hauptsächlich numerisch, hauptsächlich qualitativ, eine Mischung aus numerisch und qualitativ), und ihrem Notendurchschnitt bei Aufnahme des Programms. In diesem Fall ist die „Anzahl der Studenten der 1. Klasse“ die abhängige Variable, während „optionale Kurse“ eine nominale unabhängige Variable und „GPA“ eine kontinuierliche unabhängige Variable ist.
Nach der Durchführung einer Poisson-Regression können Sie feststellen, welche Ihrer unabhängigen Variablen (falls vorhanden) einen statistisch signifikanten Effekt auf Ihre abhängige Variable haben. Bei kategorialen unabhängigen Variablen können Sie die prozentuale Zunahme oder Abnahme der Anzahl einer Gruppe (z. B. Todesfälle unter „Kindern“, die Achterbahn fahren) im Vergleich zu einer anderen Gruppe (z. B. Todesfälle unter „Erwachsenen“, die Achterbahn fahren) bestimmen. Bei kontinuierlichen unabhängigen Variablen können Sie interpretieren, wie eine Erhöhung oder Verringerung dieser Variablen um eine Einheit mit einer prozentualen Erhöhung oder Verringerung der Anzahl der abhängigen Variablen verbunden ist (z. B. eine Verringerung des Gehalts um 1.000 $ – die unabhängige Variable – auf die prozentuale Veränderung der Anzahl der Fälle, in denen Menschen in Australien mit der Rückzahlung ihrer Kreditkarten in Verzug geraten – die abhängige Variable).
Diese Schnellstartanleitung zeigt Ihnen, wie Sie die Poisson-Regression mit SPSS Statistics durchführen und die Ergebnisse dieses Tests interpretieren und auswerten. Bevor wir Sie jedoch in dieses Verfahren einführen, müssen Sie die verschiedenen Annahmen verstehen, die Ihre Daten erfüllen müssen, damit die Poisson-Regression ein gültiges Ergebnis liefert. Diese Annahmen werden im Folgenden erörtert.
Hinweis: Derzeit gibt es keine Premium-Version dieses Leitfadens im Abonnement-Teil unserer Website.
SPSS-Statistik
Annahmen
Wenn Sie sich dafür entscheiden, Ihre Daten mit Hilfe der Poisson-Regression zu analysieren, müssen Sie unter anderem prüfen, ob die Daten, die Sie analysieren möchten, tatsächlich mit Hilfe der Poisson-Regression analysiert werden können. Dies ist notwendig, weil die Poisson-Regression nur dann sinnvoll ist, wenn Ihre Daten fünf Annahmen „erfüllen“, die erforderlich sind, damit die Poisson-Regression ein gültiges Ergebnis liefert. In der Praxis wird die Überprüfung dieser fünf Annahmen den größten Teil Ihrer Zeit in Anspruch nehmen, wenn Sie eine Poisson-Regression durchführen. Dies ist jedoch unerlässlich, da es nicht selten vorkommt, dass Daten gegen eine oder mehrere dieser Annahmen verstoßen (d. h. diese nicht erfüllen). Aber selbst wenn Ihre Daten einige dieser Annahmen nicht erfüllen, gibt es oft eine Lösung, um dieses Problem zu lösen. Schauen wir uns zunächst diese fünf Annahmen an:
- Annahme 1: Ihre abhängige Variable besteht aus Zähldaten. Zähldaten unterscheiden sich von den Daten, die in anderen bekannten Regressionsarten gemessen werden (z. B. erfordern lineare Regression und multiple Regression abhängige Variablen, die auf einer „kontinuierlichen“ Skala gemessen werden, binomiale logistische Regression erfordert eine abhängige Variable, die auf einer „dichotomen“ Skala gemessen wird, ordinale Regression erfordert eine abhängige Variable, die auf einer „ordinalen“ Skala gemessen wird, und multinomiale logistische Regression erfordert eine abhängige Variable, die auf einer „nominalen“ Skala gemessen wird). Im Gegensatz dazu erfordern Zählvariablen ganzzahlige Daten, die Null oder größer sein müssen. Vereinfacht ausgedrückt ist eine „ganze Zahl“ eine „ganze“ Zahl (z. B. 0, 1, 5, 8, 354, 888, 23400 usw.). Da Zähldaten „positiv“ sein müssen (d. h. aus „nicht-negativen“ ganzzahligen Werten bestehen), können sie nicht aus „Minus“-Werten bestehen (z. B. würden Werte wie -1, -5, -8, -354, -888 und -23400 nicht als Zähldaten gelten). Außerdem wird manchmal vorgeschlagen, die Poisson-Regression nur dann durchzuführen, wenn der Mittelwert der Zählung ein kleiner Wert ist (z. B. weniger als 10). Bei einer großen Anzahl von Zählungen könnte eine andere Art von Regression angemessener sein (z. B. multiple Regression, Gamma-Regression usw.).
Beispiele für Zählvariablen sind die Anzahl der Flüge, die auf europäischen Flughäfen mehr als drei Stunden Verspätung haben, die Anzahl der Schüler, die von Schulen in Washington in den Vereinigten Staaten suspendiert werden, die Anzahl der Fälle, in denen Menschen in Australien in einem Zeitraum von fünf Jahren mit der Rückzahlung ihrer Kreditkarten in Verzug geraten, die Anzahl der Personen, die vor Ihnen in der Warteschlange der Notaufnahme eines Krankenhauses stehen, die Anzahl der Studenten, die in einem MBA-Studiengang die Note 1 erhalten (in der Regel weniger als 5), und die Anzahl der Menschen, die bei Achterbahnunfällen in den Vereinigten Staaten ums Leben kommen. - Annahme Nr. 2: Sie haben eine oder mehrere unabhängige Variablen, die auf einer kontinuierlichen, ordinalen oder nominalen/dichotomen Skala gemessen werden können. Ordinale und nominale/dichotome Variablen lassen sich grob als kategoriale Variablen klassifizieren.
Beispiele für kontinuierliche Variablen sind Revisionszeit (gemessen in Stunden), Intelligenz (gemessen mit dem IQ-Score), Prüfungsleistung (gemessen von 0 bis 100) und Gewicht (gemessen in kg). Beispiele für ordinale Variablen sind Likert-Items (z. B. eine 7-Punkte-Skala von „stimme voll und ganz zu“ bis „stimme überhaupt nicht zu“) und andere Möglichkeiten der Einstufung von Kategorien (z. B. eine 3-Punkte-Skala, die angibt, wie sehr ein Kunde ein Produkt mochte, von „nicht sehr“ bis „doch, sehr“). Beispiele für nominale Variablen sind das Geschlecht (z. B. zwei Gruppen – männlich und weiblich – also eine dichotome Variable), die ethnische Zugehörigkeit (z. B. drei Gruppen: Weiße, Afroamerikaner und Hispanoamerikaner) und der Beruf (z. B. fünf Gruppen: Chirurg, Arzt, Krankenschwester, Zahnarzt, Therapeut). Denken Sie daran, dass ordinale und nominale/dichotome Variablen im Großen und Ganzen als kategoriale Variablen klassifiziert werden können. Mehr über Variablen erfahren Sie in unserem Artikel: Typen von Variablen. - Annahme Nr. 3: Die Beobachtungen sollten unabhängig sein. Das bedeutet, dass jede Beobachtung unabhängig von den anderen Beobachtungen ist, d.h. eine Beobachtung kann keine Informationen über eine andere Beobachtung liefern. Dies ist eine sehr wichtige Annahme. Ein Mangel an unabhängigen Beobachtungen ist meist ein Problem des Studiendesigns. Eine Methode, um die Möglichkeit der Unabhängigkeit von Beobachtungen zu testen, ist der Vergleich von modellbasierten Standardfehlern mit robusten Fehlern, um festzustellen, ob es große Unterschiede gibt.
- Annahme Nr. 4: Die Verteilung der Zählungen (bedingt durch das Modell) folgt einer Poisson-Verteilung. Eine Folge davon ist, dass die beobachteten und erwarteten Zählungen gleich sein sollten (in Wirklichkeit sind sie nur sehr ähnlich). Im Wesentlichen bedeutet dies, dass das Modell die beobachteten Zahlen gut vorhersagt. Eine Methode besteht darin, die erwarteten Zählungen zu berechnen und diese mit den beobachteten Zählungen zu vergleichen, um zu sehen, ob sie ähnlich sind.
- Annahme Nr. 5: Der Mittelwert und die Varianz des Modells sind identisch. Dies ist eine Folge der Annahme Nr. 4, dass es sich um eine Poisson-Verteilung handelt. Bei einer Poisson-Verteilung hat die Varianz den gleichen Wert wie der Mittelwert. Wenn diese Annahme erfüllt ist, liegt Äquidispersion vor. Oft ist dies jedoch nicht der Fall und Ihre Daten sind entweder unter- oder überdispers, wobei Überdispersion das häufigere Problem ist. Es gibt eine Reihe von Methoden, mit denen Sie die Überdispersion beurteilen können. Eine Methode ist die Bewertung der Pearson-Dispersionsstatistik.
Die Annahmen Nr. 3, 4 und 5 können Sie mit SPSS Statistics überprüfen. Die Annahmen Nr. 1 und 2 sollten zuerst überprüft werden, bevor man zu den Annahmen Nr. 3, 4 und 5 übergeht. Denken Sie daran, dass die Ergebnisse der Poisson-Regression ungültig sein können, wenn Sie die statistischen Tests für diese Annahmen nicht korrekt durchführen.
Wenn Ihre Daten die Annahme 5 verletzen, was bei der Durchführung der Poisson-Regression sehr häufig vorkommt, müssen Sie zunächst prüfen, ob Sie eine „scheinbare Poisson-Überdispersion“ haben. Scheinbare Poisson-Überdispersion liegt vor, wenn Sie das Modell nicht korrekt spezifiziert haben, so dass die Daten überdispers erscheinen. Wenn also Ihr Poisson-Modell anfänglich gegen die Annahme der Gleichverteilung verstößt, sollten Sie zunächst eine Reihe von Anpassungen an Ihrem Poisson-Modell vornehmen, um zu prüfen, ob es tatsächlich überdispers ist. Dazu müssen Sie sechs Überprüfungen Ihres Modells bzw. Ihrer Daten durchführen: (a) Enthält Ihr Poisson-Modell alle wichtigen Prädiktoren?; (b) Enthalten Ihre Daten Ausreißer?; (c) Enthält Ihre Poisson-Regression alle relevanten Interaktionsterme?; (d) Muss einer Ihrer Prädiktoren transformiert werden?; (e) Benötigt Ihr Poisson-Modell mehr Daten und/oder sind Ihre Daten zu spärlich?und (f) Haben Sie fehlende Werte, die nicht zufällig fehlen (MAR)?
Im Abschnitt „Vorgehensweise“ wird das SPSS Statistics-Verfahren zur Durchführung einer Poisson-Regression unter der Annahme erläutert, dass keine Annahmen verletzt wurden. Zunächst stellen wir das Beispiel vor, das in diesem Leitfaden verwendet wird.
SPSS Statistics
Beispiel & Setup in SPSS Statistics
Der Forschungsdirektor einer kleinen Universität möchte beurteilen, ob die Erfahrung eines Wissenschaftlers und die ihm zur Verfügung stehende Zeit für die Forschung die Anzahl seiner Veröffentlichungen beeinflusst. Daher wird eine Zufallsstichprobe von 21 Akademikern der Universität gebeten, an der Untersuchung teilzunehmen: 10 sind erfahrene Akademiker und 11 junge Akademiker. Erfasst werden die Anzahl der Stunden, die sie in den letzten 12 Monaten für die Forschung aufgewendet haben, und die Anzahl der von ihnen erstellten begutachteten Veröffentlichungen.
Um dieses Studiendesign in SPSS Statistics einzurichten, haben wir drei Variablen erstellt: (1) no_of_publications, d.h. die Anzahl der Publikationen, die der Wissenschaftler in den letzten 12 Monaten in begutachteten Zeitschriften veröffentlicht hat; (2) experience_of_academic, die angibt, ob der Wissenschaftler erfahren ist (d.h. seit 10 Jahren oder mehr in der Wissenschaft tätig ist und daher als „erfahrener Wissenschaftler“ eingestuft wird) oder erst seit kurzem als Wissenschaftler tätig ist (d.h., weniger als 3 Jahre, aber mindestens ein Jahr im akademischen Bereich gearbeitet hat und daher als „Recent academic“ eingestuft wird); und (3) no_of_weekly_hours, das die Anzahl der Stunden angibt, die ein Wissenschaftler pro Woche für die Forschung zur Verfügung hat.
SPSS Statistics
Testverfahren in SPSS Statistics
Die folgenden 13 Schritte zeigen Ihnen, wie Sie Ihre Daten mit Hilfe der Poisson-Regression in SPSS Statistics analysieren können, wenn keine der fünf Annahmen im vorherigen Abschnitt „Annahmen“ verletzt wurden. Am Ende dieser 13 Schritte zeigen wir Ihnen, wie Sie die Ergebnisse Ihrer Poisson-Regression interpretieren können.
- Klicken Sie im Hauptmenü auf Analysieren > Verallgemeinerte lineare Modelle > Verallgemeinerte lineare Modelle… im Hauptmenü, wie unten gezeigt:

Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Das Dialogfeld Verallgemeinerte lineare Modelle wird wie folgt angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Wählen Sie Poisson loglinear im Bereich , wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis: Während Sie standardmäßig Poisson loglinear im Bereich
auswählen, um eine Poisson-Regression durchzuführen, können Sie auch eine benutzerdefinierte Poisson-Regression ausführen, indem Sie Benutzerdefiniert im Bereich auswählen und dann die Art des Poisson-Modells angeben, das Sie mithilfe der Optionen Verteilung:, Verknüpfungsfunktion: und -Parameter- ausführen möchten. - Wählen Sie die Registerkarte . Es wird das folgende Dialogfeld angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Übertragen Sie Ihre abhängige Variable, no_of_publications, in das Feld Abhängige Variable: im Bereich
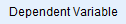 mit der Schaltfläche , wie unten gezeigt:
mit der Schaltfläche , wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Wählen Sie die Registerkarte . Das folgende Dialogfeld wird angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Übertragen Sie die kategoriale unabhängige Variable „Erfahrung_der_Akademiker“ in das Feld „Faktoren“ und die kontinuierliche unabhängige Variable „Anzahl_der_Wochenstunden“ in das Feld „Kovariaten“, indem Sie die Schaltflächen verwenden, wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis 1: Wenn Sie ordinale unabhängige Variablen haben, müssen Sie entscheiden, ob diese als kategorisch behandelt und in das Feld Faktoren: eingegeben werden sollen oder als kontinuierlich behandelt und in das Feld Kovariaten: eingegeben werden sollen. Sie können nicht als ordinale Variablen in eine Poisson-Regression eingegeben werden.
Anmerkung 2: Während es üblich ist, kontinuierliche unabhängige Variablen in das Feld Kovariaten: einzugeben, ist es möglich, stattdessen ordinale unabhängige Variablen einzugeben. In diesem Fall wird Ihre ordinale unabhängige Variable jedoch als kontinuierlich behandelt.
Hinweis 3: Wenn Sie auf die Schaltfläche
klicken, wird das folgende Dialogfeld angezeigt:
Im Bereich -Kategorienreihenfolge für Faktoren- können Sie zwischen den Optionen Aufsteigend, Absteigend und Datenreihenfolge verwenden wählen. Diese Optionen sind nützlich, weil SPSS Statistics Ihre kategorialen Variablen automatisch in Dummy-Variablen umwandelt. Wenn Sie mit Dummy-Variablen nicht vertraut sind, kann dies die Interpretation der Ergebnisse einer Poisson-Regression für die einzelnen Gruppen Ihrer kategorialen Variablen etwas erschweren. Daher können Änderungen an den Optionen im Bereich -Kategorienreihenfolge für Faktoren- die Interpretation Ihrer Ergebnisse erleichtern. - Wählen Sie die Registerkarte . Es wird das folgende Dialogfeld angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Behalten Sie die Voreinstellung im Bereich -Build Term(s)- bei und übertragen Sie die kategorialen und kontinuierlichen unabhängigen Variablen Erfahrung_von_Akademikern und Keine_wöchentlichen_Stunden aus dem Feld Faktoren und Kovariaten: in das Feld Modell:, indem Sie die Schaltfläche verwenden, wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis 1: In der Dialogbox
erstellen Sie Ihr Poisson-Modell. Insbesondere legen Sie fest, welche Haupteffekte Sie haben (Option ) und ob Sie erwarten, dass es Wechselwirkungen zwischen Ihren unabhängigen Variablen gibt (Option ). Wenn Sie vermuten, dass es Wechselwirkungen zwischen Ihren unabhängigen Variablen gibt, ist es wichtig, diese in Ihr Modell einzubeziehen, nicht nur, um die Vorhersage Ihres Modells zu verbessern, sondern auch, um Probleme mit übermäßiger Streuung zu vermeiden, wie im Abschnitt „Annahmen“ bereits hervorgehoben wurde.
Während wir ein Beispiel für ein sehr einfaches Modell mit nur einem einzigen Haupteffekt (zwischen den kategorialen und kontinuierlichen unabhängigen Variablen Erfahrung_von_Akademikern und Keine_wöchentlichen_Stunden) liefern, können Sie problemlos komplexere Modelle eingeben, indem Sie die Felder, , . und im Bereich -Build Term(s)- je nach Art der Haupteffekte und Interaktionen, die Sie in Ihrem Modell haben.Hinweis 2: Sie können auch verschachtelte Terme in Ihr Modell einbauen, indem Sie diese in das Feld Term: im Bereich -Build Nested Term- eintragen. Wir haben in diesem Modell keine verschachtelten Effekte, aber es gibt viele Szenarien, in denen Sie verschachtelte Terme in Ihrem Modell haben könnten.
- Wählen Sie die Registerkarte . Es wird das folgende Dialogfeld angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Behalten Sie die ausgewählten Standardoptionen bei.
Hinweis: Es gibt eine Reihe verschiedener Optionen, die Sie im Bereich -Parameterschätzung- auswählen können, einschließlich der Möglichkeit, eine andere zu wählen: (a) Skalierungsparametermethode (d.h.
oder statt im Feld Skalierungsparametermethode:), die in Betracht gezogen werden könnte, um mit Problemen der Überdispersion umzugehen; und (b) Kovarianzmatrix (d.h. robuster Schätzer statt modellbasierter Schätzer im Bereich -Kovarianzmatrix-), die eine weitere mögliche Option (neben anderen) darstellt, um mit Problemen der Überdispersion umzugehen.
Auch im Bereich -Iterationen- gibt es eine Reihe von Angaben, die Sie machen können, um mit Problemen der Nicht-Konvergenz in Ihrem Poisson-Modell umzugehen. - Wählen Sie den Reiter . Es wird das folgende Dialogfeld angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Wählen Sie im Bereich die Option Exponentialparameterschätzungen einbeziehen, wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis 1: Im Bereich
können Sie zwischen dem Wald- und dem Likelihood-Verhältnis wählen, basierend auf Faktoren wie dem Stichprobenumfang und den Auswirkungen, die dies auf die Genauigkeit der statistischen Signifikanztests haben kann.
Im Bereich kann auch der Lagrange-Multiplikator-Test nützlich sein, um festzustellen, ob das Poisson-Modell für Ihre Daten geeignet ist (obwohl dies nicht mit dem Poisson-Regressionsverfahren durchgeführt werden kann).Hinweis 2: Sie können auch eine breite Palette anderer Optionen auf den Registerkarten
und auswählen. Dazu gehören Optionen, die bei der Untersuchung von Unterschieden zwischen den Gruppen Ihrer kategorialen Variablen sowie beim Testen der Annahmen der Poisson-Regression wichtig sind, wie im Abschnitt „Annahmen“ bereits erläutert. - Klicken Sie auf die Schaltfläche . Dadurch wird die Ausgabe generiert.
SPSS Statistics
Interpretieren und Berichten der Ausgabe der Poisson-Regressionsanalyse
SPSS Statistics generiert eine ganze Reihe von Ausgabetabellen für eine Poisson-Regressionsanalyse. In diesem Abschnitt zeigen wir Ihnen die acht wichtigsten Tabellen, die Sie benötigen, um die Ergebnisse der Poisson-Regressionsanalyse zu verstehen, vorausgesetzt, dass keine Annahmen verletzt wurden.
Modell- und Variableninformationen
Die erste Tabelle in der Ausgabe ist die Tabelle mit den Modellinformationen (wie unten gezeigt). Sie bestätigt, dass die abhängige Variable die „Anzahl der Veröffentlichungen“ ist, die Wahrscheinlichkeitsverteilung „Poisson“ und die Verknüpfungsfunktion der natürliche Logarithmus (d. h. „Log“) ist. Wenn Sie eine Poisson-Regression mit Ihren eigenen Daten durchführen, wird der Name der abhängigen Variable anders lauten, aber die Wahrscheinlichkeitsverteilung und die Verknüpfungsfunktion werden die gleichen sein.
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Die zweite Tabelle, Case Processing Summary, zeigt Ihnen, wie viele Fälle (z. B., Probanden) in Ihre Analyse eingeschlossen wurden (Zeile „Eingeschlossen“) und wie viele nicht eingeschlossen wurden (Zeile „Ausgeschlossen“), sowie den Prozentsatz von beiden. Die Zeile „Ausgeschlossen“ zeigt die Fälle (z. B. Probanden) an, bei denen ein oder mehrere Werte fehlten. Wie Sie unten sehen können, gab es in dieser Analyse 21 Probanden ohne ausgeschlossene Probanden (d. h. ohne fehlende Werte).
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Die Tabelle „Informationen zu kategorischen Variablen“ zeigt die Anzahl und den Prozentsatz der Fälle (z. B. Probanden) in jeder Gruppe jeder unabhängigen kategorischen Variable in Ihrer Analyse. In dieser Analyse gibt es nur eine kategoriale unabhängige Variable (auch als „Faktor“ bezeichnet), nämlich Erfahrung_der_Akademie. Sie können sehen, dass die Gruppen zahlenmäßig ziemlich ausgeglichen sind (d. h. 10 gegenüber 11). Stark unausgewogene Gruppengrößen können Probleme mit der Modellanpassung verursachen, aber wir können sehen, dass es hier kein Problem gibt.
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Die Tabelle „Kontinuierliche Variableninformationen“ kann eine rudimentäre Überprüfung der Daten auf etwaige Probleme bieten, ist aber weniger nützlich als andere deskriptive Statistiken, die Sie separat ausführen können, bevor Sie die Poisson-Regression durchführen. Das Beste, was Sie aus dieser Tabelle herausholen können, ist, ein Verständnis dafür zu bekommen, ob es in Ihrer Analyse eine Überdispersion geben könnte (d. h. Annahme Nr. 5 der Poisson-Regression). Sie können dies tun, indem Sie das Verhältnis der Varianz (das Quadrat der Spalte „Std. Deviation“) zum Mittelwert (die Spalte „Mean“) für die abhängige Variable betrachten. Sie können diese Zahlen unten sehen:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Der Mittelwert ist 2,29 und die Varianz ist 2,81 (1,677582), was ein Verhältnis von 2,81 ÷ 2,29 = 1,23 ist. Bei einer Poisson-Verteilung wird ein Verhältnis von 1 angenommen (d. h. Mittelwert und Varianz sind gleich). Wir können also feststellen, dass vor der Hinzufügung von erklärenden Variablen eine geringe Überstreuung vorliegt. Wir müssen diese Annahme jedoch überprüfen, wenn alle unabhängigen Variablen zur Poisson-Regression hinzugefügt wurden. Dies wird im nächsten Abschnitt erörtert.
Bestimmen, wie gut das Modell passt
Die Tabelle der Anpassungsgüte bietet viele Maße, die verwendet werden können, um zu beurteilen, wie gut das Modell passt. Wir konzentrieren uns jedoch auf den Wert in der Spalte „Wert/df“ für die Zeile „Pearson Chi-Quadrat“, der in diesem Beispiel 1,108 beträgt, wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Ein Wert von 1 bedeutet Äquidispersion, während Werte größer als 1 auf Überdispersion und Werte unter 1 auf Unterdispersion hinweisen. Der häufigste Verstoß gegen die Annahme der Äquidispersion ist die Überdispersion. Bei einem so kleinen Stichprobenumfang wie in diesem Beispiel ist ein Wert von 1,108 wahrscheinlich kein ernsthafter Verstoß gegen diese Annahme.
Die Tabelle des Omnibus-Tests liegt irgendwo zwischen diesem und dem nächsten Abschnitt. Es handelt sich um einen Likelihood-Ratio-Test, der zeigt, ob alle unabhängigen Variablen zusammen das Modell gegenüber dem reinen Achsenabschnitt-Modell (d. h. ohne zusätzliche unabhängige Variablen) verbessern. Mit allen unabhängigen Variablen in unserem Beispielmodell haben wir einen p-Wert von 0,006 (d. h., p = 0,006), was auf ein statistisch signifikantes Gesamtmodell hinweist, wie unten in der Spalte „Sig.“ gezeigt wird:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Nachdem Sie nun wissen, dass die Hinzufügung aller unabhängigen Variablen ein statistisch signifikantes Modell erzeugt, möchten Sie wissen, welche spezifischen unabhängigen Variablen statistisch signifikant sind. Dies wird im nächsten Abschnitt erörtert.
Modelleffekte und statistische Signifikanz der unabhängigen Variablen
Die Tabelle „Tests der Modelleffekte“ (wie unten dargestellt) zeigt die statistische Signifikanz jeder der unabhängigen Variablen in der Spalte „Sig.“ an:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Der Modellabschnitt ist normalerweise nicht von Interesse. Es zeigt sich jedoch, dass die Erfahrung des Akademikers statistisch nicht signifikant ist (p = .644), die Anzahl der wöchentlich geleisteten Arbeitsstunden jedoch statistisch signifikant ist (p = .030). Diese Tabelle ist vor allem für kategoriale unabhängige Variablen nützlich, da sie die einzige Tabelle ist, die den Gesamteffekt einer kategorialen Variablen berücksichtigt, im Gegensatz zur Tabelle Parameterschätzungen, wie unten gezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Diese Tabelle enthält sowohl die Koeffizientenschätzungen (Spalte „B“) der Poisson-Regression als auch die exponentiellen Werte der Koeffizienten (Spalte „Exp(B)“). Letztere sind in der Regel aussagekräftiger. Diese potenzierten Werte können auf mehr als eine Weise interpretiert werden, und wir werden Ihnen in diesem Leitfaden eine Möglichkeit zeigen. Nehmen wir zum Beispiel die Anzahl der wöchentlich geleisteten Arbeitsstunden (d. h. die Zeile „no_of_weekly_hours“). Der potenzierte Wert ist 1,044. Das bedeutet, dass die Zahl der Veröffentlichungen (d. h. die Anzahl der abhängigen Variablen) für jede zusätzliche Wochenarbeitsstunde um das 1,044-fache steigt. Anders ausgedrückt: Für jede zusätzliche Wochenarbeitsstunde steigt die Zahl der Veröffentlichungen um 4,4 %. Eine ähnliche Interpretation kann für die kategoriale Variable vorgenommen werden.
Zusammenfassend
Die Ergebnisse für die Anzahl der pro Woche geleisteten Arbeitsstunden könnten wie folgt formuliert werden:
- Allgemein
Eine Poisson-Regression wurde durchgeführt, um die Anzahl der Publikationen vorherzusagen, die ein Wissenschaftler in den letzten 12 Monaten veröffentlicht hat, und zwar auf der Grundlage der Erfahrung des Wissenschaftlers und der Anzahl der Stunden, die ein Wissenschaftler pro Woche für die Forschung aufwendet. Für jede zusätzliche Stunde, die pro Woche für die Forschung aufgewendet wurde, wurden 1,044 (95% CI, 1,004 bis 1,085) mal mehr Publikationen veröffentlicht, ein statistisch signifikantes Ergebnis, p = .030.