
Bevor ich mich auf die Reise machte, um Informatik zu lernen, gab es bestimmte Begriffe und Phrasen, die mich dazu brachten, in die andere Richtung zu rennen.
Aber anstatt zu rennen, täuschte ich Wissen vor, nickte in Unterhaltungen mit und tat so, als wüsste ich, worauf sich jemand bezog, obwohl ich in Wahrheit keine Ahnung hatte und eigentlich ganz aufgehört hatte zuzuhören, als ich den Super Scary Computer Science Term™ hörte. Im Laufe dieser Serie habe ich es geschafft, ein großes Gebiet abzudecken, und viele dieser Begriffe sind tatsächlich viel weniger beängstigend geworden!
Es gibt jedoch einen großen Begriff, den ich eine Zeit lang vermieden habe. Bis jetzt fühlte ich mich jedes Mal, wenn ich diesen Begriff hörte, wie gelähmt. Er tauchte in lockeren Gesprächen bei Treffen und manchmal bei Konferenzen auf. Jedes Mal denke ich an Maschinen, die sich drehen, und an Computer, die Codefolgen ausspucken, die nicht zu entziffern sind, außer dass alle anderen um mich herum sie entziffern können, so dass eigentlich nur ich nicht weiß, was vor sich geht (hoppla, wie konnte das passieren?!).
Vielleicht bin ich nicht die Einzige, der es so geht. Aber ich nehme an, ich sollte dir sagen, was dieser Begriff eigentlich bedeutet, oder? Nun, machen Sie sich bereit, denn ich beziehe mich auf den immer schwer fassbaren und scheinbar verwirrenden abstrakten Syntaxbaum, kurz AST. Nach vielen Jahren der Einschüchterung freue ich mich, endlich keine Angst mehr vor diesem Begriff zu haben und wirklich zu verstehen, worum es sich dabei handelt.
Es ist an der Zeit, sich der Wurzel des abstrakten Syntaxbaums zu stellen – und unser Parsing-Spiel zu verbessern!
Jedes gute Unterfangen beginnt mit einer soliden Grundlage, und unsere Mission, diese Struktur zu entmystifizieren, sollte genau so beginnen: mit einer Definition natürlich!
Ein abstrakter Syntaxbaum (gewöhnlich einfach als AST bezeichnet) ist eigentlich nichts anderes als eine vereinfachte, verkürzte Version eines Parse-Baums. Im Kontext des Compilerentwurfs wird der Begriff „AST“ austauschbar mit Syntaxbaum verwendet.

Wir denken oft über Syntaxbäume (und wie sie konstruiert werden) im Vergleich zu ihren Parse-Tree-Gegenstücken nach, mit denen wir bereits ziemlich vertraut sind. Wir wissen, dass Parse-Bäume Baumdatenstrukturen sind, die die grammatikalische Struktur unseres Codes enthalten; mit anderen Worten, sie enthalten alle syntaktischen Informationen, die in einem Code-„Satz“ vorkommen, und werden direkt aus der Grammatik der Programmiersprache selbst abgeleitet.
Ein abstrakter Syntaxbaum hingegen ignoriert einen beträchtlichen Teil der syntaktischen Informationen, die ein Parse-Baum sonst enthalten würde.
Im Gegensatz dazu enthält ein AST nur die Informationen, die sich auf die Analyse des Ausgangstextes beziehen, und überspringt alle anderen zusätzlichen Inhalte, die beim Parsen des Textes verwendet werden.
Diese Unterscheidung beginnt viel mehr Sinn zu machen, wenn wir uns auf die „Abstraktheit“ eines AST konzentrieren.
Wir erinnern uns daran, dass ein Parse-Baum eine illustrierte, bildliche Version der grammatischen Struktur eines Satzes ist. Mit anderen Worten: Ein Parse-Baum stellt genau das dar, wie ein Ausdruck, ein Satz oder ein Text aussieht. Er ist im Grunde eine direkte Übersetzung des Textes selbst; wir nehmen den Satz und verwandeln jedes kleine Stück davon – von der Zeichensetzung über die Ausdrücke bis hin zu den Token – in eine Baumdatenstruktur. Sie zeigt die konkrete Syntax eines Textes, weshalb sie auch als konkreter Syntaxbaum oder CST bezeichnet wird. Wir verwenden den Begriff konkret, um diese Struktur zu beschreiben, weil sie eine grammatikalische Kopie unseres Codes ist, Token für Token, im Baumformat.
Aber was macht etwas konkret im Gegensatz zu abstrakt? Nun, ein abstrakter Syntaxbaum zeigt uns nicht genau, wie ein Ausdruck aussieht, so wie es ein Parse-Baum tut.

Ein abstrakter Syntaxbaum zeigt uns vielmehr die „wichtigen“ Teile – die Dinge, die uns wirklich wichtig sind und die unserem Code-„Satz“ selbst Bedeutung verleihen. Syntaxbäume zeigen uns die wichtigen Teile eines Ausdrucks oder die abstrahierte Syntax unseres Ausgangstextes. Im Vergleich zu konkreten Syntaxbäumen sind diese Strukturen also abstrakte Darstellungen unseres Codes (und in gewisser Weise weniger genau), was ihnen auch ihren Namen eingebracht hat.
Nachdem wir nun den Unterschied zwischen diesen beiden Datenstrukturen und die verschiedenen Arten, wie sie unseren Code darstellen können, verstanden haben, lohnt es sich, die Frage zu stellen: Wo passt ein abstrakter Syntaxbaum in den Compiler? Erinnern wir uns zunächst an alles, was wir bisher über den Kompilierungsprozess wissen.

Sagen wir, wir haben einen super kurzen und süßen Quelltext, der wie folgt aussieht: 5 + (1 x 12).
Wir erinnern uns, dass das erste, was im Kompilierungsprozess passiert, das Scannen des Textes ist, eine Aufgabe, die vom Scanner ausgeführt wird, was dazu führt, dass der Text in seine kleinstmöglichen Teile zerlegt wird, die Lexeme genannt werden. Dieser Teil ist sprachunabhängig, und am Ende erhalten wir die zerlegte Version unseres Ausgangstextes.
Als nächstes werden genau diese Lexeme an den Lexer/Tokenizer weitergegeben, der diese kleinen Repräsentationen unseres Ausgangstextes in Token umwandelt, die für unsere Sprache spezifisch sind. Unsere Token sehen dann etwa so aus: . Die gemeinsame Arbeit des Scanners und des Tokenisierers bildet die lexikalische Analyse der Kompilierung.
Nachdem unsere Eingabe in Token umgewandelt wurde, werden die daraus resultierenden Token an unseren Parser weitergegeben, der dann den Quelltext nimmt und daraus einen Parse-Baum erstellt. Die folgende Abbildung zeigt beispielhaft, wie unser tokenisierter Code in Form eines Parse-Baums aussieht.
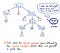
Die Arbeit der Umwandlung von Token in einen Parse-Baum wird auch als Parsen bezeichnet und ist als Syntaxanalysephase bekannt. Die Phase der Syntaxanalyse hängt direkt von der Phase der lexikalischen Analyse ab; daher muss die lexikalische Analyse im Kompilierungsprozess immer an erster Stelle stehen, denn der Parser unseres Compilers kann seine Arbeit erst erledigen, wenn der Tokenizer seine Arbeit erledigt hat!
Wir können uns die Teile des Compilers als gute Freunde vorstellen, die alle voneinander abhängen, um sicherzustellen, dass unser Code korrekt von einem Text oder einer Datei in einen Parse-Baum umgewandelt wird.
Aber zurück zu unserer ursprünglichen Frage: Wo passt der abstrakte Syntaxbaum in diese Freundesgruppe? Nun, um diese Frage zu beantworten, hilft es, die Notwendigkeit eines AST überhaupt zu verstehen.
Kondensieren eines Baumes in einen anderen
Okay, jetzt haben wir also zwei Bäume, die wir in unserem Kopf behalten müssen. Wir hatten bereits einen Parse-Baum, und jetzt müssen wir noch eine weitere Datenstruktur lernen! Und offensichtlich ist diese AST-Datenstruktur nur ein vereinfachter Parse-Baum. Wozu brauchen wir sie also? Wozu brauchen wir ihn überhaupt?
Werfen wir doch mal einen Blick auf unseren Parse-Baum?
Wir wissen bereits, dass Parse-Bäume unser Programm in seinen deutlichsten Teilen repräsentieren; das war ja auch der Grund, warum der Scanner und der Tokenizer so wichtige Aufgaben haben, unseren Ausdruck in seine kleinsten Teile zu zerlegen!
Was bedeutet es eigentlich, ein Programm in seinen deutlichsten Teilen zu repräsentieren?
Wie sich herausstellt, sind manchmal alle einzelnen Teile eines Programms für uns gar nicht so nützlich.
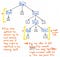
Werfen wir einen Blick auf die hier gezeigte Abbildung, die unseren ursprünglichen Ausdruck 5 + (1 x 12) im Parse-Tree-Format darstellt. Wenn wir diesen Baum mit einem kritischen Auge betrachten, werden wir sehen, dass es ein paar Fälle gibt, in denen ein Knoten genau ein Kind hat, die auch als Single-Successor-Knoten bezeichnet werden, da sie nur einen Kindknoten haben, der von ihnen abstammt (oder einen „Nachfolger“).
Im Fall unseres Parse-Baum-Beispiels haben die Single-Successor-Knoten einen Parent-Knoten von Expression oder Exp, die einen einzigen Nachfolger von irgendeinem Wert haben, wie 5, 1 oder 12. Die Exp-Elternknoten hier bringen uns jedoch nichts wirklich Wertvolles, oder? Wir können sehen, dass sie Token/Terminal-Kinderknoten enthalten, aber der Elternknoten „Ausdruck“ ist uns eigentlich egal; wir wollen nur wissen, wie der Ausdruck lautet?
Der Elternknoten gibt uns überhaupt keine zusätzlichen Informationen, sobald wir unseren Baum geparst haben. Was uns wirklich interessiert, ist der einzige Kindknoten, der einzige Nachfolgeknoten. Das ist nämlich der Knoten, der uns die wichtigen Informationen liefert, der Teil, der für uns von Bedeutung ist: die Zahl und der Wert selbst! In Anbetracht der Tatsache, dass diese übergeordneten Knoten für uns irgendwie unnötig sind, wird klar, dass dieser Parse-Baum ziemlich langatmig ist.
Alle diese Single-Successor-Knoten sind für uns ziemlich überflüssig und helfen uns überhaupt nicht weiter. Schaffen wir sie also ab!
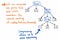
Wenn wir die Einzel-Nachfolger-Knoten in unserem Parse-Baum komprimieren, erhalten wir eine stärker komprimierte Version der exakt gleichen Struktur. In der obigen Abbildung sehen wir, dass wir immer noch genau dieselbe Verschachtelung wie zuvor beibehalten, und unsere Knoten/Token/Terminale erscheinen immer noch an der richtigen Stelle im Baum. Aber wir haben es geschafft, ihn ein wenig zu verschlanken.
Und wir können auch noch mehr von unserem Baum abschneiden. Wenn wir uns zum Beispiel unseren Parse-Baum in seiner jetzigen Form ansehen, werden wir feststellen, dass er eine Spiegelstruktur enthält. Der Unterausdruck von (1 x 12) ist in Klammern () verschachtelt, die ihrerseits Token sind.
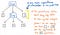
Diese Klammern helfen uns jedoch nicht wirklich weiter, wenn wir unseren Baum einmal aufgebaut haben. Wir wissen bereits, dass 1 und 12 Argumente sind, die an die Multiplikation x übergeben werden, also sagen uns die Klammern an dieser Stelle nicht viel. In der Tat könnten wir unseren Parse-Baum noch weiter komprimieren und diese überflüssigen Blattknoten loswerden.
Wenn wir unseren Parse-Baum komprimieren und vereinfachen und den überflüssigen syntaktischen „Staub“ loswerden, erhalten wir eine Struktur, die an dieser Stelle sichtbar anders aussieht. Diese Struktur ist in der Tat unser neuer und lang erwarteter Freund: der abstrakte Syntaxbaum.

Das obige Bild zeigt genau denselben Ausdruck wie unser Parse-Baum: 5 + (1 x 12). Der Unterschied ist, dass der Ausdruck von der konkreten Syntax abstrahiert wurde. Wir sehen keine Klammern () mehr in diesem Baum, weil sie nicht notwendig sind. Ebenso sehen wir keine Nicht-Terminale wie Exp, da wir bereits herausgefunden haben, was der „Ausdruck“ ist, und wir sind in der Lage, den Wert herauszuziehen, der für uns wirklich wichtig ist – zum Beispiel die Zahl 5.
Das ist genau der Unterschied zwischen einem AST und einer CST. Wir wissen, dass ein abstrakter Syntaxbaum einen großen Teil der syntaktischen Informationen ignoriert, die ein Parse-Baum enthält, und „zusätzliche Inhalte“ auslässt, die beim Parsen verwendet werden. Aber jetzt können wir genau sehen, wie das geschieht!

Nachdem wir nun einen eigenen Parse-Baum kondensiert haben, werden wir einige der Muster, die einen AST von einem CST unterscheiden, viel besser erkennen können.
Es gibt einige Möglichkeiten, wie sich ein abstrakter Syntaxbaum visuell von einem Parse-Baum unterscheidet:
- Ein AST enthält niemals syntaktische Details wie Kommas, Klammern und Semikolons (abhängig natürlich von der Sprache).
- Ein AST hat kollabierte Versionen von Knoten, die sonst als einzelne Nachfolger erscheinen würden; er enthält niemals „Ketten“ von Knoten mit einem einzigen Kind.
- Schließlich werden alle Operator-Token (wie
+,-,xund/) zu internen (übergeordneten) Knoten im Baum und nicht zu Blättern, die in einem Parse-Baum enden.
Aus visueller Sicht wird ein AST immer kompakter erscheinen als ein Parse-Baum, da er per Definition eine komprimierte Version eines Parse-Baums mit weniger syntaktischen Details ist.
Wenn also ein AST eine komprimierte Version eines Parse-Baums ist, dann können wir nur dann einen abstrakten Syntaxbaum erstellen, wenn wir die Dinge haben, mit denen wir einen Parse-Baum erstellen können!
So fügt sich der abstrakte Syntaxbaum in den größeren Kompilierungsprozess ein. Ein AST hat eine direkte Verbindung zu den Parse-Bäumen, die wir bereits kennengelernt haben, während er sich gleichzeitig darauf verlässt, dass der Lexer seine Arbeit erledigt, bevor ein AST überhaupt erstellt werden kann.

Der abstrakte Syntaxbaum wird als Endergebnis der Syntaxanalysephase erstellt. Der Parser, der bei der Syntaxanalyse im Vordergrund steht, kann, muss aber nicht immer einen Parse-Baum (CST) erzeugen. Je nach Compiler und dessen Konzeption kann der Parser direkt zur Konstruktion eines Syntaxbaums (AST) übergehen. Aber der Parser wird immer einen AST als Ausgabe erzeugen, unabhängig davon, ob er zwischendurch einen Parse-Baum erstellt oder wie viele Durchgänge er dafür benötigt.
Anatomie eines AST
Nun, da wir wissen, dass der abstrakte Syntaxbaum wichtig ist (aber nicht unbedingt einschüchternd!), können wir ihn ein wenig mehr sezieren. Ein interessanter Aspekt beim Aufbau des AST hat mit den Knoten dieses Baums zu tun.
Das folgende Bild zeigt die Anatomie eines einzelnen Knotens in einem abstrakten Syntaxbaum.
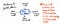
Wir werden feststellen, dass dieser Knoten anderen, die wir bereits gesehen haben, insofern ähnelt, als er einige Daten enthält (ein token und sein value). Er enthält jedoch auch einige sehr spezifische Zeiger. Jeder Knoten in einem AST enthält Verweise auf seinen nächsten Geschwisterknoten sowie auf seinen ersten Kindknoten.
Unser einfacher Ausdruck 5 + (1 x 12) könnte beispielsweise in eine visualisierte Darstellung eines AST, wie die folgende, umgewandelt werden.

Wir können uns vorstellen, dass das Lesen, Traversieren oder „Interpretieren“ dieses AST von den untersten Ebenen des Baums ausgeht und sich nach oben arbeitet, um am Ende einen Wert oder einen Rückgabewert result zu erhalten.
Es kann auch hilfreich sein, eine codierte Version der Ausgabe eines Parsers zu sehen, um unsere Visualisierungen zu ergänzen. Wir können uns auf verschiedene Tools stützen und bereits vorhandene Parser verwenden, um ein schnelles Beispiel dafür zu sehen, wie unser Ausdruck aussehen könnte, wenn er durch einen Parser läuft. Im Folgenden sehen Sie ein Beispiel für unseren Quelltext 5 + (1 * 12), der durch Esprima, einen ECMAScript-Parser, und den daraus resultierenden abstrakten Syntaxbaum gelaufen ist, gefolgt von einer Liste der einzelnen Token.
In diesem Format können wir die Verschachtelung des Baums sehen, wenn wir die verschachtelten Objekte betrachten. Es fällt auf, dass die Werte, die 1 und 12 enthalten, die left bzw. right Kinder einer übergeordneten Operation, *, sind. Wir werden auch sehen, dass die Multiplikationsoperation (*) den rechten Teilbaum des gesamten Ausdrucks selbst bildet, weshalb sie innerhalb des größeren Objekts BinaryExpression unter dem Schlüssel "right" verschachtelt ist. In ähnlicher Weise ist der Wert von 5 das einzelne "left"-Kind des größeren BinaryExpression-Objekts.

Der faszinierendste Aspekt des abstrakten Syntaxbaums ist jedoch die Tatsache, dass er, obwohl er so kompakt und sauber ist, nicht immer eine einfache Datenstruktur ist, die es zu konstruieren gilt. Tatsächlich kann die Erstellung eines AST ziemlich komplex sein, je nachdem, mit welcher Sprache der Parser zu tun hat!
Die meisten Parser erstellen entweder einen Parse-Baum (CST) und konvertieren ihn dann in ein AST-Format, weil das manchmal einfacher ist – auch wenn es mehr Schritte und im Allgemeinen mehr Durchläufe durch den Quelltext bedeutet. Die Erstellung eines CST ist eigentlich ziemlich einfach, wenn der Parser die Grammatik der Sprache kennt, die er zu parsen versucht. Er braucht keine komplizierte Arbeit zu leisten, um herauszufinden, ob ein Token „signifikant“ ist oder nicht; stattdessen nimmt er einfach genau das, was er sieht, in der spezifischen Reihenfolge, in der er es sieht, und spuckt es alles in einen Baum aus.
Andererseits gibt es einige Parser, die versuchen, all dies in einem einzigen Schritt zu tun, indem sie direkt einen abstrakten Syntaxbaum konstruieren.
Die direkte Erstellung eines AST kann schwierig sein, da der Parser nicht nur die Token finden und korrekt darstellen muss, sondern auch entscheiden muss, welche Token für uns von Bedeutung sind und welche nicht.
Beim Compilerentwurf ist der AST aus mehr als einem Grund sehr wichtig. Ja, er kann schwierig zu konstruieren sein (und ist wahrscheinlich leicht zu vermasseln), aber er ist auch das letzte und endgültige Ergebnis der lexikalischen und syntaktischen Analysephasen zusammen! Die Phasen der lexikalischen und der Syntaxanalyse werden oft gemeinsam als Analysephase oder Front-End des Compilers bezeichnet.

Wir können uns den abstrakten Syntaxbaum als das „Endprojekt“ des Front-Ends des Compilers vorstellen. Er ist der wichtigste Teil, denn er ist das letzte, was das Frontend von sich zeigen muss. Der Fachausdruck dafür heißt Zwischencode-Darstellung oder IR, weil es die Datenstruktur ist, die letztendlich vom Compiler verwendet wird, um einen Quelltext darzustellen.
Ein abstrakter Syntaxbaum ist die gebräuchlichste Form der IR, aber manchmal auch die am meisten missverstandene. Aber jetzt, wo wir ihn ein wenig besser verstehen, können wir anfangen, unsere Wahrnehmung dieser beängstigenden Struktur zu ändern! Hoffentlich ist sie jetzt etwas weniger einschüchternd für uns.
Ressourcen
Es gibt eine ganze Reihe von Ressourcen über ASTs in einer Vielzahl von Sprachen. Zu wissen, wo man anfangen soll, kann schwierig sein, besonders wenn man mehr lernen möchte. Nachfolgend finden Sie einige anfängerfreundliche Ressourcen, die viel mehr ins Detail gehen, ohne zu sehr zu erdrücken. Happy asbtracting!
- The AST vs the Parse Tree, Professor Charles N. Fischer
- What’s the difference between parse trees and abstract syntax trees? StackOverflow
- Abstrakte vs. Konkrete Syntaxbäume, Eli Bendersky
- Abstrakte Syntaxbäume, Professor Stephen A. Edwards
- Abstrakte Syntaxbäume & Top-Down Parsing, Professor Konstantinos (Kostis) Sagonas
- Lexikalische und Syntaxanalyse von Programmiersprachen, Chris Northwood
- AST Explorer, Felix Kling