Einführung
Wenn Sie Ihre Daten mittels multipler Regression analysieren und eine Ihrer unabhängigen Variablen auf einer nominalen oder ordinalen Skala gemessen wurde, müssen Sie wissen, wie Sie Dummy-Variablen erstellen und deren Ergebnisse interpretieren können. Dies liegt daran, dass nominale und ordinale unabhängige Variablen, die allgemein als kategoriale unabhängige Variablen bezeichnet werden, nicht direkt in eine multiple Regressionsanalyse eingegeben werden können. Stattdessen müssen sie in Dummy-Variablen umgewandelt werden. Eine Ausnahme bilden ordinale unabhängige Variablen, die als kontinuierliche unabhängige Variablen in eine multiple Regression eingegeben werden, die nicht in Dummy-Variablen umgewandelt werden müssen. In diesem Leitfaden zeigen wir Ihnen daher, wie Sie Dummy-Variablen erstellen, wenn Sie kategoriale unabhängige Variablen haben.
Zunächst erläutern wir anhand eines Beispiels, wie Sie Dummy-Variablen in SPSS Statistics erstellen können, bevor wir erklären, wie Sie Ihre Daten in den Fenstern Variablenansicht und Datenansicht von SPSS Statistics einrichten, damit Sie Dummy-Variablen erstellen können. Wenn Sie mit der Verwendung von Dummy-Variablen nicht vertraut sind, empfehlen wir Ihnen, einige der grundlegenden Prinzipien von Dummy-Variablen und Dummy-Codierung nachzulesen, darunter: (a) die Anzahl der Dummy-Variablen, die Sie in Ihrer Analyse erstellen müssen; und (b) wie Sie Dummy-Variablen und Dummy-Codierung erstellen. Im folgenden Abschnitt „Verfahren“ wird das einfache, dreistufige Verfahren zur Erstellung von Dummy-Variablen in SPSS Statistics beschrieben, das zur Erstellung von Dummy-Variablen verwendet werden kann. Abschließend wird die Ausgabe von SPSS Statistics nach Ausführung der Prozedur „Dummy-Variablen erstellen“ erläutert, einschließlich der Darstellung der Dummy-Variablen in den Fenstern „Variablenansicht“ und „Datenansicht“ von SPSS Statistics.
Hinweis: Wenn Sie der Meinung sind, dass die Prozeduren in diesem Leitfaden die Art von Dummy-Variablen, die Sie erstellen möchten, nicht abdecken, wenden Sie sich bitte an uns. Möglicherweise können wir der Website einen weiteren Leitfaden hinzufügen, um Ihnen zu helfen.
SPSS Statistics
Beispiel in diesem Leitfaden
In diesem Leitfaden wird das Beispiel von 10 Triathleten verwendet, die gebeten wurden, ihre Lieblingssportart aus den drei Sportarten auszuwählen, die sie bei einem Triathlon betreiben: Schwimmen, Radfahren und Laufen. Ihre Antworten wurden in der unabhängigen nominalen Variable Lieblingssportart erfasst, die drei Kategorien umfasst: „Schwimmen“, „Radfahren“ und „Laufen“. Diese nominale unabhängige Variable, Lieblingssportart, sollte in eine multiple Regressionsanalyse einbezogen werden, die auch eine Reihe von kontinuierlichen unabhängigen Variablen enthielt. Da es sich bei dieser unabhängigen Variable um eine kategoriale Variable handelte (d. h., nominale und ordinale Variablen können im Großen und Ganzen als kategoriale Variablen klassifiziert werden), mussten Dummy-Variablen erstellt werden, bevor sie in die multiple Regressionsanalyse aufgenommen werden konnte.
Wichtig: Beachten Sie, dass es sich bei Lieblingssport um eine nominale Variable handelt, aber Sie können auch Dummy-Variablen für eine ordinale Variable erstellen. Außerdem ist das Verfahren zur Erstellung von Dummy-Variablen unabhängig davon, ob es sich um eine ordinale oder nominale Variable handelt, dasselbe, mit Ausnahme einer kleinen Änderung, die Sie beim Einrichten Ihrer Daten vornehmen müssen und die im Folgenden erläutert wird.
Anmerkung 1: Die „Kategorien“ einer kategorialen unabhängigen Variable werden auch als „Gruppen“ oder „Stufen“ bezeichnet, aber der Begriff „Stufen“ ist in der Regel für Kategorien reserviert, die eine Ordnung haben (z. B. könnte die ordinale unabhängige Variable „Fitnessniveau“ drei Stufen haben: „niedrig“, „mittel“ und „hoch“). Diese drei Begriffe – „Kategorien“, „Gruppen“ und „Stufen“ – können jedoch austauschbar verwendet werden. In diesem Leitfaden werden wir sie als Kategorien bezeichnen, aber Sie können sie auch als Gruppen oder Stufen bezeichnen, wenn Sie dies bevorzugen.
Anmerkung 2: Der Begriff „Faktoren“ wird manchmal anstelle von „kategorialen unabhängigen Variablen“ (d. h. unabhängigen Variablen, die „ordinal“ oder „nominal“ sind) verwendet. Diese beiden Begriffe – „kategoriale unabhängige Variablen“ und „Faktoren“ – können jedoch austauschbar verwendet werden. In diesem Handbuch werden sie als kategoriale unabhängige Variablen bezeichnet, und Sie werden auch sehen, dass SPSS Statistics sie in seinem Verfahren der multiplen Regression als unabhängige Variablen und nicht als Faktoren bezeichnet. Sie können sie jedoch als Faktoren bezeichnen, wenn Sie dies bevorzugen.
SPSS Statistics
Einrichten Ihrer Daten in SPSS Statistics
Bei der Erstellung von Dummy-Variablen beginnen Sie mit einer einzelnen kategorialen unabhängigen Variablen (z. B. Lieblingssport). Um diese kategoriale unabhängige Variable einzurichten, verfügt SPSS Statistics über eine Variablenansicht, in der Sie die Variablentypen definieren, die Sie analysieren, und eine Datenansicht, in die Sie Ihre Daten für diese Variable eingeben. In diesem Abschnitt zeigen wir Ihnen zunächst, wie Sie eine kategoriale unabhängige Variable im Fenster Variablenansicht von SPSS Statistics einrichten, bevor wir Ihnen zeigen, wie Sie Ihre Daten in das Fenster Datenansicht eingeben. Dazu verwenden wir unsere kategoriale unabhängige Variable Lieblingssportart, die drei Kategorien hat: „Schwimmen“, „Radfahren“ und „Laufen“.
Die Variablenansicht in SPSS Statistics
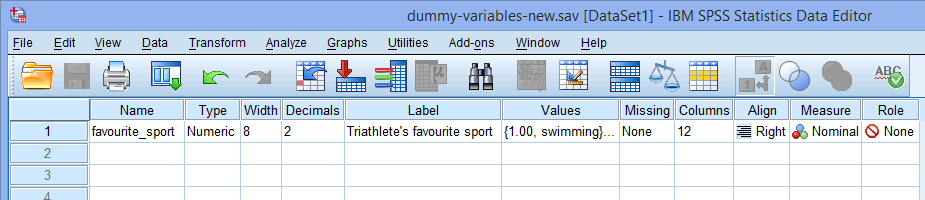
Für eine einzelne kategoriale unabhängige Variable (z. B., favourite_sport) sieht das Fenster Variablenansicht wie folgt aus:
Hinweis: Sie können auf das Fenster Variablenansicht in SPSS Statistics zugreifen, indem Sie auf die Registerkarte ![]() in der linken unteren Ecke der SPSS Statistics-Software klicken.
in der linken unteren Ecke der SPSS Statistics-Software klicken.
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Der Name Ihrer kategorialen unabhängigen Variable sollte in die Zelle unter der Spalte ![]() eingegeben werden (z. B., „favourite_sport“ in Zeile
eingegeben werden (z. B., „favourite_sport“ in Zeile ![]() , um unsere kategoriale unabhängige Variable „favourite_sport“ darzustellen. Es gibt bestimmte „illegale“ Zeichen, die nicht in die Zelle
, um unsere kategoriale unabhängige Variable „favourite_sport“ darzustellen. Es gibt bestimmte „illegale“ Zeichen, die nicht in die Zelle ![]() eingegeben werden können. Wenn Sie eine Fehlermeldung erhalten und möchten, dass wir einen SPSS-Statistics-Leitfaden hinzufügen, um zu erklären, was diese unzulässigen Zeichen sind, wenden Sie sich bitte an uns.
eingegeben werden können. Wenn Sie eine Fehlermeldung erhalten und möchten, dass wir einen SPSS-Statistics-Leitfaden hinzufügen, um zu erklären, was diese unzulässigen Zeichen sind, wenden Sie sich bitte an uns.
Hinweis: Der Übersichtlichkeit halber können Sie auch eine Bezeichnung für Ihre Variablen in der Spalte ![]() angeben. Die Bezeichnung, die wir für „Lieblingssport“ eingegeben haben, lautet zum Beispiel „Lieblingssport des Triathleten“.
angeben. Die Bezeichnung, die wir für „Lieblingssport“ eingegeben haben, lautet zum Beispiel „Lieblingssport des Triathleten“.
Die Zelle unter der Spalte ![]() sollte die Informationen über die Kategorien Ihrer kategorialen unabhängigen Variablen enthalten (z. B. „Schwimmen“, „Radfahren“ und „Laufen“ für Lieblingssport. Um diese Informationen einzugeben, klicken Sie in die Zelle unter der Spalte
sollte die Informationen über die Kategorien Ihrer kategorialen unabhängigen Variablen enthalten (z. B. „Schwimmen“, „Radfahren“ und „Laufen“ für Lieblingssport. Um diese Informationen einzugeben, klicken Sie in die Zelle unter der Spalte ![]() für Ihre unabhängige Variable. Die Schaltfläche
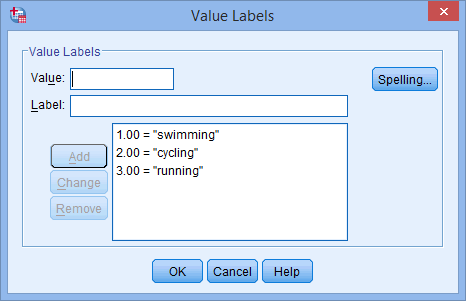
für Ihre unabhängige Variable. Die Schaltfläche ![]() wird in der Zelle angezeigt. Klicken Sie auf diese Schaltfläche und das Dialogfeld Wertelabels wird angezeigt. Sie müssen nun jeder Kategorie Ihrer unabhängigen Variablen einen „Wert“ geben, den Sie in das Feld Wert: eingeben (z. B. „1“), sowie eine „Bezeichnung“, die Sie in das Feld Bezeichnung: eingeben (z. B. „Schwimmen“). Wenn Sie auf die Schaltfläche
wird in der Zelle angezeigt. Klicken Sie auf diese Schaltfläche und das Dialogfeld Wertelabels wird angezeigt. Sie müssen nun jeder Kategorie Ihrer unabhängigen Variablen einen „Wert“ geben, den Sie in das Feld Wert: eingeben (z. B. „1“), sowie eine „Bezeichnung“, die Sie in das Feld Bezeichnung: eingeben (z. B. „Schwimmen“). Wenn Sie auf die Schaltfläche ![]() klicken, wird die Kodierung im Hauptfeld angezeigt (z. B. „1.00=“Schwimmen“ für Lieblingssport). Das Setup für unsere kategoriale unabhängige Variable wird im folgenden Dialogfeld „Value Labels“ angezeigt:
klicken, wird die Kodierung im Hauptfeld angezeigt (z. B. „1.00=“Schwimmen“ für Lieblingssport). Das Setup für unsere kategoriale unabhängige Variable wird im folgenden Dialogfeld „Value Labels“ angezeigt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Die Zelle unter der Spalte ![]() sollte
sollte ![]() anzeigen, wenn Sie eine nominale unabhängige Variable haben (z. B., Lieblingssport, wie in unserem Beispiel) oder
anzeigen, wenn Sie eine nominale unabhängige Variable haben (z. B., Lieblingssport, wie in unserem Beispiel) oder ![]() , wenn Sie eine ordinale unabhängige Variable haben (stellen Sie sich z. B. eine ordinale Variable wie „Body Mass Index“ (BMI) vor, BMI), die vier Stufen hat: „Untergewicht“, „Gesundes/Normalgewicht“, „Übergewicht“ und „Fettleibigkeit“). Schließlich sollte die Zelle unter der Spalte
, wenn Sie eine ordinale unabhängige Variable haben (stellen Sie sich z. B. eine ordinale Variable wie „Body Mass Index“ (BMI) vor, BMI), die vier Stufen hat: „Untergewicht“, „Gesundes/Normalgewicht“, „Übergewicht“ und „Fettleibigkeit“). Schließlich sollte die Zelle unter der Spalte ![]()
![]() .
.
Hinweis: Wir schlagen vor, die Zelle unter der Spalte ![]() von
von ![]() in
in ![]() zu ändern, aber Sie müssen diese Änderung nicht vornehmen. Wir empfehlen Ihnen, dies zu tun, da es bestimmte Analysen in SPSS Statistics gibt, bei denen die Einstellung
zu ändern, aber Sie müssen diese Änderung nicht vornehmen. Wir empfehlen Ihnen, dies zu tun, da es bestimmte Analysen in SPSS Statistics gibt, bei denen die Einstellung ![]() dazu führt, dass Ihre Variablen automatisch in bestimmte Felder der von Ihnen verwendeten Dialogfelder übertragen werden. Da Sie diese Variablen möglicherweise nicht übertragen möchten, empfehlen wir Ihnen, die Einstellung
dazu führt, dass Ihre Variablen automatisch in bestimmte Felder der von Ihnen verwendeten Dialogfelder übertragen werden. Da Sie diese Variablen möglicherweise nicht übertragen möchten, empfehlen wir Ihnen, die Einstellung ![]() in
in ![]() zu ändern, damit dies nicht automatisch geschieht.
zu ändern, damit dies nicht automatisch geschieht.
Sie haben nun erfolgreich alle Informationen, die SPSS Statistics über Ihre kategoriale unabhängige Variable wissen muss, in das Fenster Variablenansicht eingegeben. Im nächsten Abschnitt zeigen wir Ihnen, wie Sie Ihre Daten in das Fenster „Datenansicht“ eingeben.
Die Datenansicht in SPSS Statistics
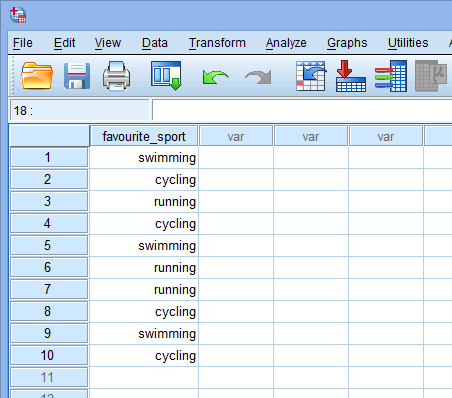
Auf der Grundlage der Dateieinrichtung für Ihre kategoriale unabhängige Variable im Fenster „Variablenansicht“ oben sieht das Fenster „Datenansicht“ wie folgt aus:
Hinweis: Sie können auf das Fenster „Datenansicht“ in SPSS Statistics zugreifen, indem Sie auf die Registerkarte ![]() in der linken unteren Ecke der SPSS Statistics-Software klicken.
in der linken unteren Ecke der SPSS Statistics-Software klicken.
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Ihre kategoriale unabhängige Variable wird in der ersten Spalte angezeigt, da dies die Reihenfolge war, in der wir die Variable in das Fenster Variablenansicht eingegeben haben. In unserem Beispiel werden die Antworten der 10 Triathleten in der Spalte ![]() angezeigt. Nun müssen Sie nur noch Ihre Daten in die Zellen unter dieser ersten Spalte eingeben. Denken Sie daran, dass jede Zeile einen Fall darstellt (ein Fall kann z. B. ein einzelner Teilnehmer sein). In Zeile
angezeigt. Nun müssen Sie nur noch Ihre Daten in die Zellen unter dieser ersten Spalte eingeben. Denken Sie daran, dass jede Zeile einen Fall darstellt (ein Fall kann z. B. ein einzelner Teilnehmer sein). In Zeile ![]() unseres Beispiels steht der erste Fall also für einen Triathleten, dessen Lieblingssportart „Schwimmen“ ist. Da diese Zellen zunächst leer sind, müssen Sie in die Zellen klicken, um Ihre Daten einzugeben. Wenn Sie in die Zellen unter der Spalte
unseres Beispiels steht der erste Fall also für einen Triathleten, dessen Lieblingssportart „Schwimmen“ ist. Da diese Zellen zunächst leer sind, müssen Sie in die Zellen klicken, um Ihre Daten einzugeben. Wenn Sie in die Zellen unter der Spalte ![]() klicken, zeigt SPSS Statistics eine Dropdown-Option an, in der die Kategorien bereits ausgefüllt sind.
klicken, zeigt SPSS Statistics eine Dropdown-Option an, in der die Kategorien bereits ausgefüllt sind.
Nachdem Sie Ihre Daten in den Fenstern Variablenansicht und Datenansicht von SPSS Statistics eingerichtet haben, empfehlen wir Ihnen, den nächsten Abschnitt zu lesen: Dummy-Variablen und Dummy-Codierung verstehen, in dem wir die Grundprinzipien von Dummy-Variablen und Dummy-Codierung erklären. Wenn Sie jedoch bereits mit den Grundlagen von Dummy-Variablen und Dummy-Codierung vertraut sind, können Sie diesen Abschnitt überspringen und direkt zum Abschnitt Prozedur übergehen, in dem wir die Prozedur Dummy-Variablen erstellen in SPSS Statistics beschreiben, die zur Erstellung von Dummy-Variablen verwendet wird.
SPSS Statistics
Verstehen von Dummy-Variablen und Dummy-Codierung
Wie in der Einleitung erwähnt, müssen Sie wissen, wie Sie Dummy-Variablen erstellen und ihre Ergebnisse interpretieren können, wenn Sie Ihre Daten mithilfe der multiplen Regression analysieren und eine Ihrer unabhängigen Variablen auf einer nominalen oder ordinalen Skala gemessen wurde. Dies liegt daran, dass kategoriale unabhängige Variablen (d. h. nominale und ordinale unabhängige Variablen) nicht direkt in eine multiple Regression eingegeben werden können. Stattdessen müssen sie in Dummy-Variablen umgewandelt werden. Eine Ausnahme bilden ordinale unabhängige Variablen, die als kontinuierliche unabhängige Variablen in eine multiple Regression eingegeben werden, die nicht in Dummy-Variablen umgewandelt werden müssen. In den folgenden Abschnitten wird erläutert: (a) die Anzahl der zu erstellenden Dummy-Variablen und (b) die Erstellung von Dummy-Variablen und die Dummy-Codierung.
Die Anzahl der zu erstellenden Dummy-Variablen
Die Anzahl der zu erstellenden Dummy-Variablen hängt davon ab, wie viele Kategorien Ihre kategoriale unabhängige Variable hat. In der Regel erstellen Sie eine Dummy-Variable weniger als die Anzahl der Kategorien in Ihrer kategorialen unabhängigen Variablen. Wenn Sie z. B. eine kategoriale unabhängige Variable mit drei Kategorien haben (z. B. Lieblingssportart, mit den folgenden drei Kategorien: „Schwimmen“, „Radfahren“ und „Laufen“), erstellen Sie zwei Dummy-Variablen und wählen eine Kategorie als Referenzkategorie aus (z. B. werden „Schwimmen“ und „Radfahren“ zu Dummy-Variablen und „Laufen“ wird die Referenzkategorie). Nach der folgenden Tabelle, die einige Beispiele für kategoriale unabhängige Variablen und die Anzahl der zu erstellenden Dummy-Variablen enthält, wird mehr über Referenzkategorien erklärt:
| Name der kategorialen unabhängigen Variablen | Typ der Variablen | Anzahl der Kategorien | Anzahl der Dummy-Variablen | ||||
|---|---|---|---|---|---|---|---|
| 1 | Geschlecht | Nominal | Zwei (Männer &Frauen) |
Eins=Männer „Frauen“ ist die Referenzkategorie |
|||
| 2 | Höhe | Ordinal | Zwei (Unter 180cm & 180cm und darüber) |
Eins=Unter 180cm „180cm und darüber“ ist die Referenzkategorie |
|||
| 3 | Ethnizität | Nominal | Drei (Afroamerikan, Kaukasisch & Hispanoamerikanisch) |
Zwei=Afrikanischamerikanisch & Kaukasisch „Hispanoamerikanisch“ ist die Referenzkategorie |
|||
| 4 | Physisches Aktivitätsniveau | Ordinal | Drei (Niedrig, Mäßig & Hoch) |
Zwei=Niedrig & Mäßig „Hoch“ ist die Referenzkategorie |
|||
| 5 | Beruf | Nominal | Vier (Chirurg, Arzt, Krankenschwester & Therapeut) |
Drei=Chirurg, Arzt & Krankenschwester „Therapeut“ ist die Referenzkategorie |
|||
| 6 | Zustimmungsgrad | Ordinal | Vier (stimme stark zu, stimme zu, stimme nicht zu, stimme überhaupt nicht zu) |
Drei=stimme voll und ganz zu, stimme zu & stimme nicht zu „stimme überhaupt nicht zu“ ist die Referenzkategorie |
|||
| 7 | Fachbereich | Nominal | Fünf (Wirtschaftswissenschaften, Psychologie, Biowissenschaften, Ingenieurwissenschaften & Recht) |
Vier=Wirtschaftswissenschaften, Psychologie, Biowissenschaften & Ingenieurwissenschaften „Recht“ ist die Referenzkategorie |
|||
| 8 | Alter | Ordinal | Fünf (Unter 18, 19-30, 31-40, 41-50, 51-60) |
Vier=Unter 18, 19-30, 31-40 & 41-50 „51-60“ ist die Referenzkategorie |
|||
| Tabelle: Beispiele für kategoriale unabhängige Variablen und ihre jeweiligen Dummy-Variablen | |||||||
Wie aus der obigen Tabelle hervorgeht, müssen Sie nur eine Dummy-Variable weniger erstellen als die Anzahl der Kategorien in Ihrer kategorialen unabhängigen Variablen. Dies liegt daran, dass Sie diese Anzahl von Dummy-Variablen nur in eine multiple Regression übertragen müssen (und sollten), wenn Sie eine kategoriale unabhängige Variable haben. Es gibt jedoch gute Gründe dafür, eine Dummy-Variable für jede Kategorie der kategorialen unabhängigen Variable zu erstellen: (a) es ist flexibler und (b) es ermöglicht Mehrfachvergleiche (siehe Anmerkung unten). Mit anderen Worten: Wenn Ihre kategoriale unabhängige Variable drei Kategorien hat, sollten Sie drei Dummy-Variablen erstellen, nicht nur zwei.
Glücklicherweise erstellt die Prozedur „Dummy-Variablen erstellen“ in SPSS Statistics Version 22 und höher automatisch eine Dummy-Variable für jede Kategorie Ihrer kategorialen unabhängigen Variable. Dies ist jedoch bei der Prozedur Umkodierung in verschiedene Variablen in SPSS Statistics Version 21 oder früher nicht der Fall. Unter normalen Umständen werden Sie daher in SPSS Statistics die folgenden Einstellungen vorgenommen haben, je nachdem, ob Sie Version 21 oder früher oder Version 22 und höher verwenden:
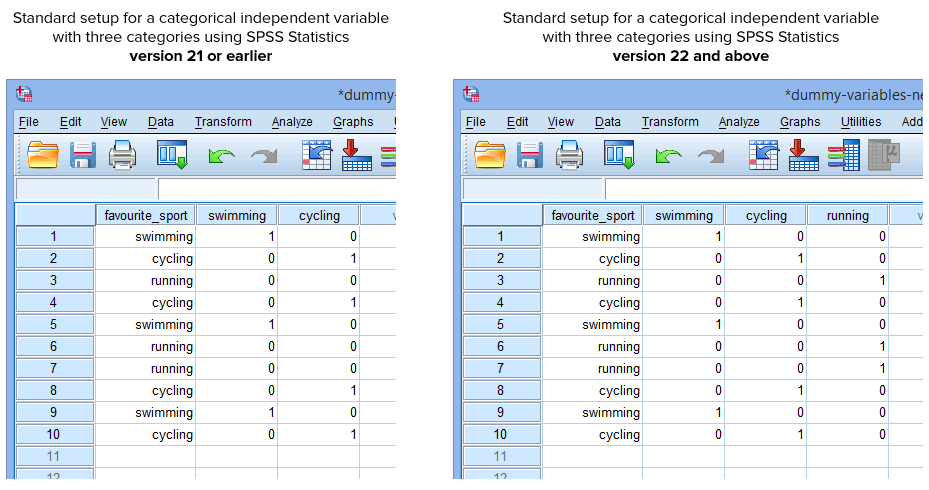
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis: Wie bereits erwähnt, ist die Erstellung einer Dummy-Variable für jede Kategorie der kategorialen unabhängigen Variable aus zwei Gründen von Vorteil: (a) sie ist flexibler und (b) sie ermöglicht mehrere Vergleiche. Wir gehen im Folgenden kurz auf diese Vorteile ein:
Sie ist flexibler:
Wenn Sie eine Dummy-Variable für jede Kategorie Ihrer kategorialen unabhängigen Variable erstellt haben, können Sie jede beliebige Kategorie als Referenzkategorie betrachten. In unserem Beispiel haben wir die Kategorie „Laufen“ als Referenzkategorie betrachtet, was bedeutet, dass wir „Schwimmen“ und „Radfahren“ in die multiple Regressionsgleichung übertragen hätten. Wenn wir jedoch später unsere Meinung über die Wahl der Referenzkategorie ändern würden, müssten wir das Dummy-Variablen-Verfahren erneut durchführen (es sei denn, Sie haben SPSS Statistics Version 22 oder höher). Nehmen wir zum Beispiel an, dass wir nun die Kategorie „Radfahren“ als Referenzkategorie betrachten wollen. Wir könnten nun die Dummy-Variablen „Schwimmen“ und „Laufen“ in die multiple Regressionsgleichung übertragen, da wir auch die Dummy-Variable „Laufen“ haben.
Sie ermöglicht mehrere Vergleiche:
Der Koeffizient einer Dummy-Variable stellt den Unterschied zwischen der Kategorie, die diese Dummy-Variable darstellt, und der Referenzkategorie dar. Wenn zum Beispiel „Laufen“ die Referenzkategorie ist, stellt der Koeffizient der Dummy-Variable „Schwimmen“ den Unterschied in der abhängigen Variable zwischen den Kategorien „Schwimmen“ und „Laufen“ dar. Bei dieser Methode sind nicht alle Kombinationen von Kategorien möglich. Dieses Problem kann durch die Verwendung verschiedener Referenzkategorien gelöst werden. Dies ist möglich, wenn alle Kategorien der kategorialen Variable eine Dummy-Variable haben.
Wie erstellt man Dummy-Variablen und Dummy-Kodierung
Es gibt zwei Schritte, um Dummy-Variablen in einer multiplen Regression erfolgreich einzurichten: (1) Erstellen Sie Dummy-Variablen, die die Kategorien Ihrer kategorialen unabhängigen Variablen darstellen; und (2) geben Sie Werte in diese Dummy-Variablen ein – bekannt als Dummy-Kodierung – um die Kategorien der kategorialen unabhängigen Variablen darzustellen. Wir erläutern diesen Prozess im Folgenden anhand des oben genannten Beispiels.
Erläuterung: Dummy-Variablen sind einfach neue Variablen, die als „Platzhalter“ für ein bestimmtes Kodierungsschema dienen. Sie enthalten per se keine Daten. Stattdessen müssen diesen Dummy-Variablen Daten/Werte hinzugefügt werden, damit sie ihren Zweck der Darstellung der Kategorien Ihrer kategorialen unabhängigen Variablen erfüllen können. Es gibt viele verschiedene Arten von Kodierungsschemata, die vorschreiben, welche Werte in Dummy-Variablen eingetragen werden, aber wir verwenden ein sehr gebräuchliches Kodierungsschema, das als Dummy-Kodierung oder alternativ als Indikator-Kodierung bezeichnet wird (Achtung, kommen Sie nicht durcheinander, denn Dummy-Variablen und Dummy-Kodierung sind nicht dasselbe). Bei der Dummy-Kodierung wird jede Dummy-Variable verwendet, um eine bestimmte Kategorie einer kategorialen unabhängigen Variablen zu identifizieren, mit Ausnahme einer Referenzkategorie, die wir weiter unten erläutern.
Betrachten wir zunächst unsere kategoriale unabhängige Variable „Lieblingssport“, die drei Kategorien hat: „Schwimmen“, „Radfahren“ und „Laufen“. Da es drei Kategorien gibt, sind zwei Dummy-Variablen erforderlich, die zwei der Kategorien repräsentieren, und eine Referenzkategorie, die die dritte Kategorie darstellt.
Hinweis: Aus der obigen Diskussion wissen Sie, dass Sie bei einer multiplen Regression eine Dummy-Variable weniger übertragen müssen als die Anzahl der Kategorien in Ihrer kategorialen unabhängigen Variablen (d. h. zwei in unserem Beispiel). Sie können jedoch für jede Kategorie der kategorialen unabhängigen Variable eine Dummy-Variable erstellen, um flexibler zu sein und mehrere Vergleiche anstellen zu können. In der nachstehenden Diskussion wird jedoch nur hervorgehoben, was für eine multiple Regression erforderlich ist, nämlich die Erstellung einer Dummy-Variable weniger als die Anzahl der Kategorien in Ihrer kategorialen unabhängigen Variablen, wobei die Kategorie, die nicht direkt repräsentiert wird, zur „Referenzkategorie“ wird.
Zum Beispiel: Die Dummy-Variable Nr. 1 steht für die Kategorie „Schwimmen“ und die Dummy-Variable Nr. 2 für die Kategorie „Radfahren“. Dann bleibt keine Dummy-Variable für die Kategorie „Laufen“ übrig. Diese „fehlende“ Kategorie ist die Referenzkategorie und wird nicht benötigt. Außerdem ist es allein Ihre Entscheidung, welche Kategorie Sie als Referenzkategorie verwenden wollen. Wir hätten genauso gut die Kategorie „Schwimmen“ als Referenzkategorie wählen können und nicht die Kategorie „Laufen“. Der einzige Grund, warum wir das nicht getan haben, ist, dass SPSS Statistics standardmäßig die letzte Kategorie, die Sie in der Variablenansicht für Ihre kategoriale unabhängige Variable kodiert haben, als Referenzkategorie verwendet (siehe Hinweis unten).
Hinweis: Wie bereits im Abschnitt Daten-Setup erläutert und unten im Dialogfeld Wertelabels angezeigt, war die dritte und letzte Kategorie unserer kategorialen unabhängigen Variable „Laufen“ (d. h., 3=“running“).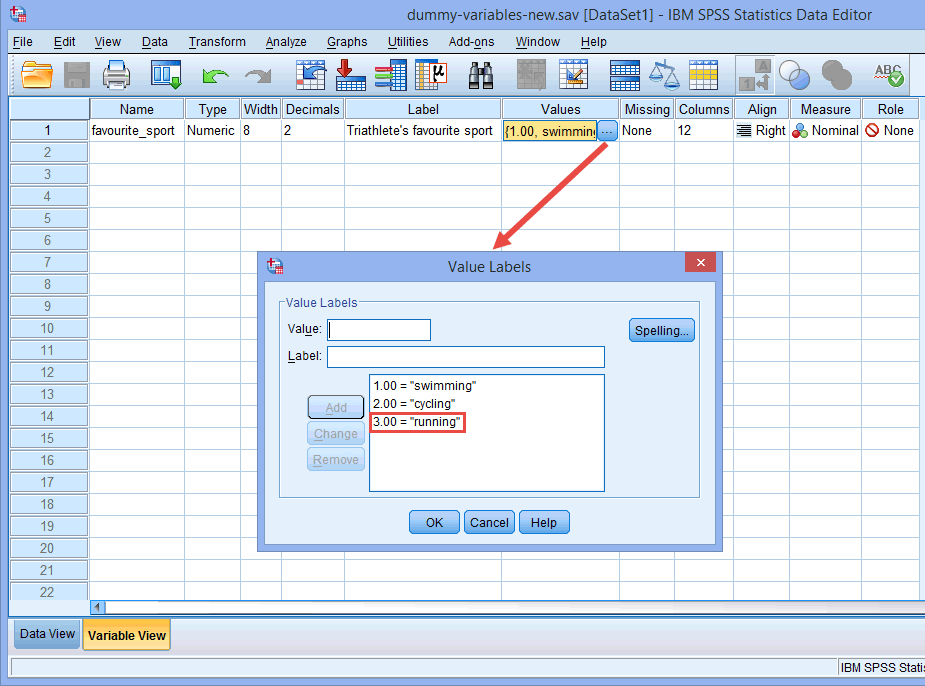
Es gab keinen theoretischen oder statistischen Grund dafür, die Kategorie „running“ zur dritten und letzten Kategorie zu machen, wodurch sie in SPSS Statistics standardmäßig zur Referenzkategorie wurde. Wir haben es einfach so gemacht, weil Triathleten, die an einem Triathlon teilnehmen, zuerst schwimmen, dann Rad fahren und schließlich ins Ziel laufen. Daher erschien es logisch, unsere kategoriale unabhängige Variable auf diese Weise zu kodieren. Wir hätten sie jedoch auch als 1=Radfahren, 2=Laufen und 3=Schwimmen kodieren können; das hätte keinen Unterschied gemacht, außer dass „Schwimmen“ als dritte und letzte Kategorie standardmäßig unsere Referenzkategorie in SPSS Statistics geworden wäre.
Wenn Sie Dummy-Variablen erstellen, sollten Sie ihnen einen aussagekräftigen Namen geben. Da jede unserer Dummy-Variablen eine Kategorie unserer kategorialen unabhängigen Variablen darstellt, ist es üblich, jede Dummy-Variable mit dem Namen der Kategorie zu bezeichnen, die sie darstellt. Daher haben wir die Dummy-Variable Nr. 1 „Schwimmen“ genannt, da sie die Kategorie Schwimmen repräsentiert. Analog dazu haben wir die Dummy-Variable Nr. 2 „Radfahren“ genannt, da sie für die Kategorie Radfahren steht. Durch die Erstellung dieser beiden Dummy-Variablen haben wir zwei neue Spalten in unserem Datensatz in SPSS Statistics, wie unten dargestellt:
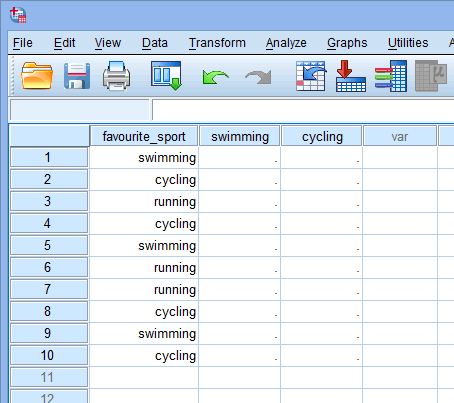
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Nun, da wir zwei Dummy-Variablen erstellt und ihnen geeignete Namen gegeben haben, müssen wir Werte in diese Variablen eingeben, damit jede Dummy-Variable wirklich die Kategorie der kategorialen unabhängigen Variablen repräsentiert. Bei der Dummy-Kodierung ist dies sehr einfach. Sie geben eine „1“ ein, um jeden Fall (z. B. einen Teilnehmer in Ihrem Datensatz) zu repräsentieren, der die Kategorie hat, und geben eine „0“ (Null) ein, wenn er die Kategorie nicht hat. Betrachten wir zunächst die Dummy-Variable „Schwimmen“, wie unten dargestellt:
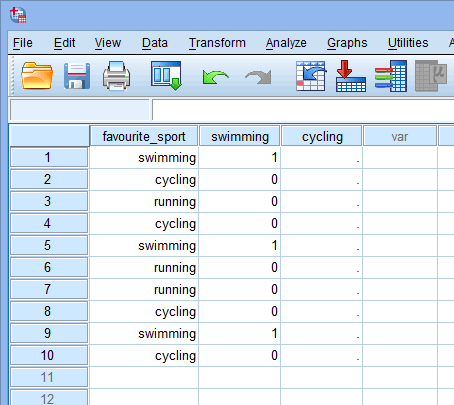
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Wenn einer der Triathleten angibt, dass „Schwimmen“ seine „Lieblings“-Sportart ist, würden wir eine „1“ in die Zelle unter der Spalte der Dummy-Variable „Schwimmen“ (![]() ) für diesen Triathleten eingeben, der angibt, dass Schwimmen seine „Lieblings“-Sportart ist. Wenn hingegen einer der Triathleten angibt, dass „Radfahren“ oder „Laufen“ seine „Lieblingssportart“ ist, würden wir eine „0“ in die Zelle unter der Spalte für die Dummy-Variable Schwimmen (
) für diesen Triathleten eingeben, der angibt, dass Schwimmen seine „Lieblings“-Sportart ist. Wenn hingegen einer der Triathleten angibt, dass „Radfahren“ oder „Laufen“ seine „Lieblingssportart“ ist, würden wir eine „0“ in die Zelle unter der Spalte für die Dummy-Variable Schwimmen (![]() ) für den Triathleten eintragen, der angibt, dass Schwimmen „nicht“ seine Lieblingssportart ist (d. h., dass entweder „Radfahren“ oder „Laufen“ die Lieblingssportart des Triathleten ist). Dies wird im Folgenden für alle 10 Triathleten hervorgehoben:
) für den Triathleten eintragen, der angibt, dass Schwimmen „nicht“ seine Lieblingssportart ist (d. h., dass entweder „Radfahren“ oder „Laufen“ die Lieblingssportart des Triathleten ist). Dies wird im Folgenden für alle 10 Triathleten hervorgehoben:
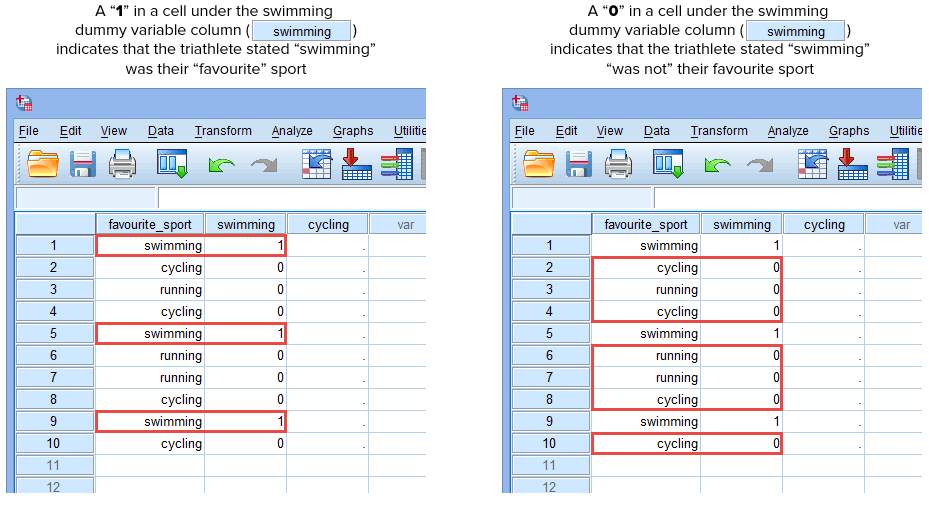
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Wir wiederholen diesen Vorgang für die andere Dummy-Variable, „Radfahren“, wie im Folgenden dargestellt:
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Wenn einer der Triathleten angibt, dass „Radsport“ seine „Lieblingssportart“ ist, würden wir für diesen Triathleten, der angibt, dass Radsport seine „Lieblingssportart“ ist, eine „1“ in die Zelle unter der Spalte der Dummy-Variable „Radsport“ (![]() ) eingeben. Wenn hingegen einer der Triathleten „Schwimmen“ oder „Laufen“ als seine „Lieblingssportart“ angibt, würden wir eine „0“ in die Zelle unter der Spalte für die Dummy-Variable „Radfahren“ (
) eingeben. Wenn hingegen einer der Triathleten „Schwimmen“ oder „Laufen“ als seine „Lieblingssportart“ angibt, würden wir eine „0“ in die Zelle unter der Spalte für die Dummy-Variable „Radfahren“ (![]() ) für diesen Triathleten eintragen, der angibt, dass Radfahren „nicht“ seine Lieblingssportart ist (d. h., dass entweder „Schwimmen“ oder „Laufen“ die Lieblingssportart dieses Triathleten ist). Dies wird im Folgenden für alle 10 Triathleten hervorgehoben:
) für diesen Triathleten eintragen, der angibt, dass Radfahren „nicht“ seine Lieblingssportart ist (d. h., dass entweder „Schwimmen“ oder „Laufen“ die Lieblingssportart dieses Triathleten ist). Dies wird im Folgenden für alle 10 Triathleten hervorgehoben:
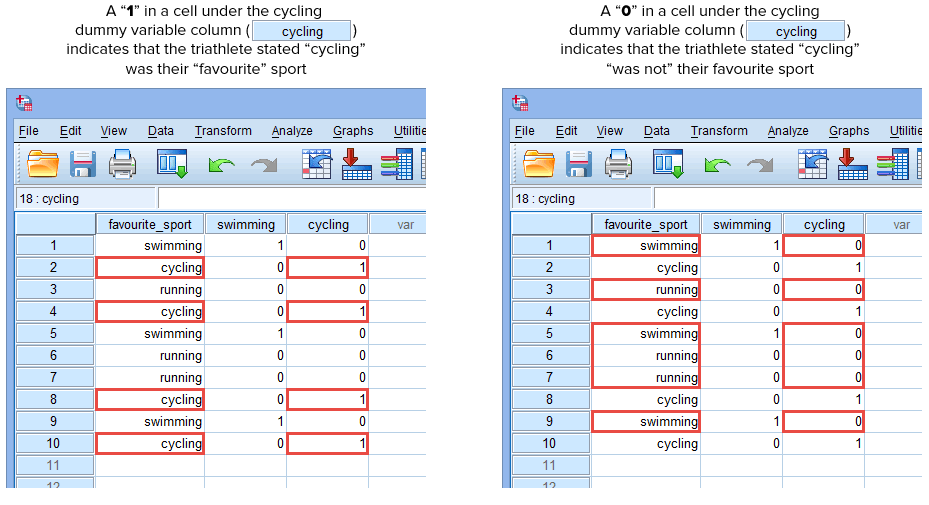
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Indem Sie auf diese Weise „1 „s und „0 „s in Ihre Dummy-Variablen eingeben, haben Sie eine Reihe von Dummy-Variablen erstellt, die Sie in eine multiple Regressionsanalyse eingeben können. Im folgenden Abschnitt „Verfahren“ zeigen wir Ihnen, wie Sie diese Dummy-Variablen mit dem Verfahren „Dummy-Variablen erstellen“ erstellen.
SPSS Statistics
Verfahren in SPSS Statistics zum Erstellen von Dummy-Variablen
Es gibt zwei Verfahren in SPSS Statistics zum Erstellen von Dummy-Variablen: das Verfahren „Dummy-Variablen erstellen“ und das Verfahren „Umkodieren in verschiedene Variablen“. In diesem Leitfaden zeigen wir Ihnen, wie Sie die Prozedur Dummy-Variablen erstellen verwenden, die ein einfaches Verfahren mit drei Schritten ist. Sie steht jedoch nur zur Verfügung, wenn Sie SPSS Statistics Version 22 oder höher haben, wobei Version 26 (und die Abonnementversion von SPSS Statistics) die neueste Version von SPSS Statistics ist. Wenn Sie sich nicht sicher sind, welche Version von SPSS Statistics Sie verwenden, lesen Sie unseren Leitfaden: Identifizierung Ihrer SPSS Statistics-Version. Wenn Sie SPSS Statistics Version 21 oder eine frühere Version verwenden oder daran interessiert sind, bei der Durchführung Ihrer multiplen Regressionsanalyse Mehrfachvergleiche durchzuführen, beachten Sie bitte den folgenden Hinweis:
Hinweis: Wenn Sie SPSS Statistics Version 21 oder eine frühere Version verwenden, können Sie die Prozedur Dummy-Variablen erstellen nicht nutzen. Daher ermöglicht Ihnen die Prozedur Umkodieren in andere Variablen zumindest die Erstellung von Dummy-Variablen in SPSS Statistics. Sie können zwar auch die Prozedur „Umkodieren in andere Variablen“ verwenden, um Dummy-Variablen zu erstellen, wenn Sie SPSS Statistics Version 22 oder höher haben, aber in diesem Handbuch wird die Prozedur „Dummy-Variablen erstellen“ vorgestellt, weil sie speziell für die Erstellung von Dummy-Variablen gedacht ist und viel einfacher und schneller zu verwenden ist. So sind beispielsweise nur 3 Schritte erforderlich, um Dummy-Variablen für das in diesem Leitfaden verwendete Beispiel zu erstellen, im Vergleich zu 28 Schritten für dasselbe Beispiel unter Verwendung der Prozedur „Umkodieren in verschiedene Variablen“.
Wenn Sie also SPSS Statistics Version 21 oder früher haben, finden Sie in unserem erweiterten Leitfaden „Erstellen von Dummy-Variablen“ im Mitgliederbereich von Laerd Statistics eine Seite, auf der gezeigt wird, wie diese 28 Schritte umfassende Prozedur „Umkodieren in verschiedene Variablen“ ausgeführt wird. Sie können auf diese erweiterte Anleitung zugreifen, indem Sie Laerd Statistics abonnieren. Alternativ können Sie auch einfach das nachstehende Verfahren zum Erstellen von Dummy-Variablen verwenden.
Um Dummy-Variablen zu erstellen, wenn Sie SPSS Statistics Version 22 oder höher haben, folgen Sie dem nachstehenden 3-Schritt-Verfahren zum Erstellen von Dummy-Variablen:
- Klicken Sie im Hauptmenü auf Transformieren > Dummy-Variablen erstellen, wie nachstehend gezeigt:

Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Das Dialogfeld „Dummy-Variablen erstellen“ wird wie folgt angezeigt:
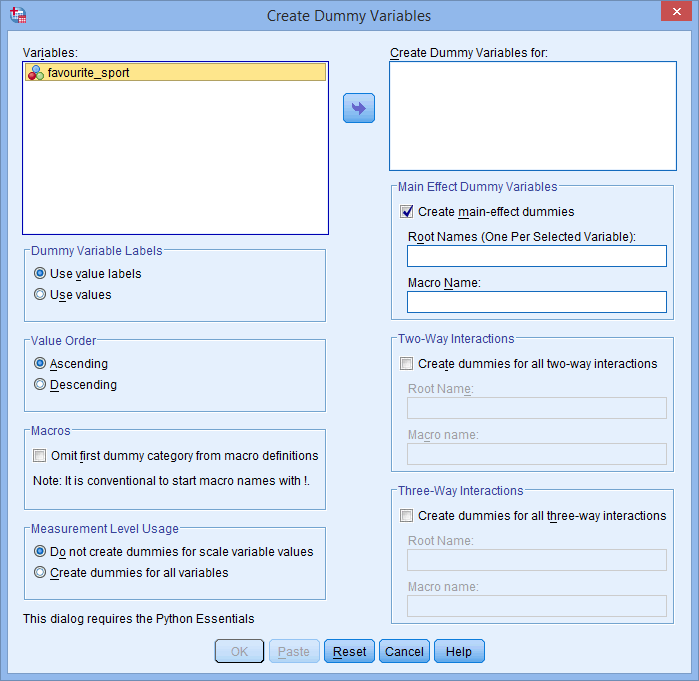
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
- Übertragen Sie die kategoriale unabhängige Variable „favourite_sport“ in das Feld „Dummy-Variablen erstellen für:“, indem Sie sie auswählen (indem Sie auf sie klicken) und dann auf die Schaltfläche
 klicken. Geben Sie außerdem einen „Stammnamen“, der für alle neuen Dummy-Variablen stehen kann, in das Feld Stammnamen (einer pro ausgewählter Variable): im Bereich -Haupteffekt-Dummy-Variablen- ein. Wir haben den Stammnamen „fs“ als Abkürzung für unsere kategoriale unabhängige Variable „favourite_sport“ eingegeben, wie unten gezeigt:
klicken. Geben Sie außerdem einen „Stammnamen“, der für alle neuen Dummy-Variablen stehen kann, in das Feld Stammnamen (einer pro ausgewählter Variable): im Bereich -Haupteffekt-Dummy-Variablen- ein. Wir haben den Stammnamen „fs“ als Abkürzung für unsere kategoriale unabhängige Variable „favourite_sport“ eingegeben, wie unten gezeigt:
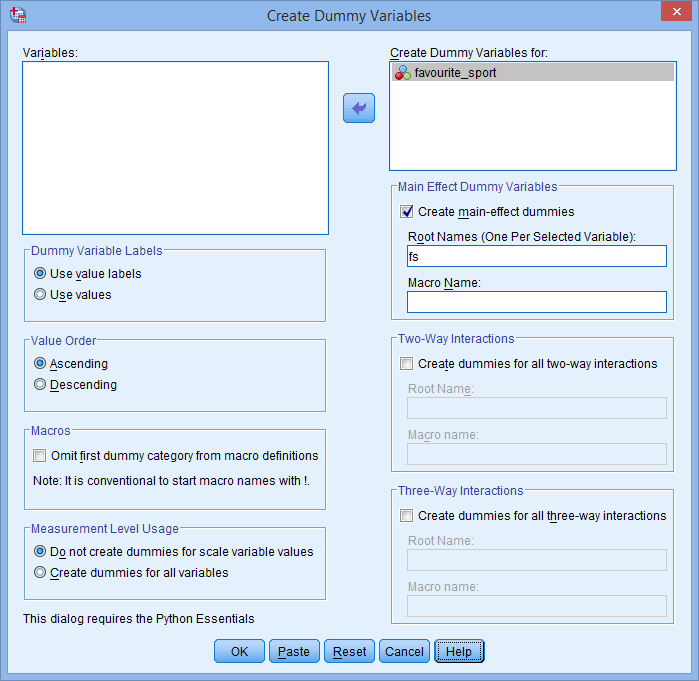
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis: SPSS Statistics fügt eine fortlaufende Nummer (d. h. 1, 2, 3, 4 usw.) am Ende des Stammnamens hinzu, den Sie für Ihre kategoriale unabhängige Variable gewählt haben. Für jede der Dummy-Variablen, die Sie erstellen möchten, wird eine fortlaufende Nummer erstellt (z. B. werden bei zwei Dummy-Variablen eine 1 und eine 2 am Ende des Stammnamens hinzugefügt, bei sechs Dummy-Variablen jedoch eine 1, 2, 3, 4, 5 und 6 am Ende des Stammnamens). Dies wird für unser Beispiel im nachstehenden Fenster Variablenansicht gezeigt:
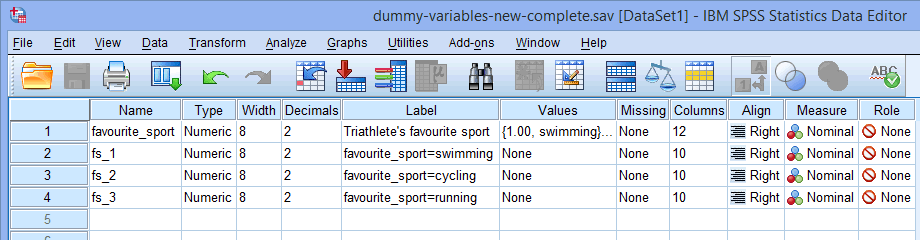
Da unsere kategoriale unabhängige Variable Lieblingssportart drei Kategorien hatte (d. h. Schwimmen, Radfahren und Laufen), erstellt die Prozedur Dummy-Variablen erstellen drei Dummy-Variablen (d. h. eine für Schwimmen, eine für Radfahren und eine für Laufen). Diese drei Dummy-Variablen sind in der Spalte oben hervorgehoben: „fs_1“ (für Schwimmen), „fs_2“ (für Radfahren) und „fs_3“ (für Laufen). Sie können diese später umbenennen, damit sie mehr Sinn ergeben. Wir heben dies nur hervor, damit Sie wissen, wie das obige Feld Root Names (One per Selected Variable): funktioniert.
oben hervorgehoben: „fs_1“ (für Schwimmen), „fs_2“ (für Radfahren) und „fs_3“ (für Laufen). Sie können diese später umbenennen, damit sie mehr Sinn ergeben. Wir heben dies nur hervor, damit Sie wissen, wie das obige Feld Root Names (One per Selected Variable): funktioniert.
Auch darf der Root Name, den Sie in das Feld Root Names (One per Selected Variable): eingeben, nicht mit dem Namen Ihrer kategorialen unabhängigen Variablen übereinstimmen, wie unten gezeigt (d.h., wobei wir den Stammnamen „favourite_sport“ eingegeben haben, um zu veranschaulichen, wie wir unseren Stammnamen nicht nennen könnten):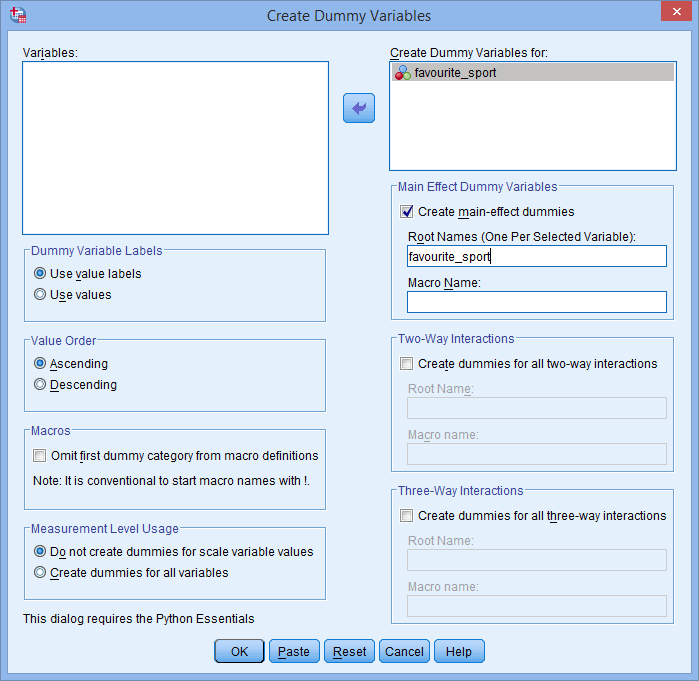
Wenn der von Ihnen eingegebene Stammname mit dem Namen Ihrer kategorialen unabhängigen Variablen übereinstimmt, wie oben gezeigt, erhalten Sie beim Klicken auf die Schaltfläche die folgende Warnung:
die folgende Warnung:
- Klicken Sie auf die Schaltfläche .
Nachdem Sie die oben beschriebene 3-Schritt-Prozedur zum Erstellen von Dummy-Variablen durchgeführt haben, haben Sie Dummy-Variablen für Ihre kategoriale unabhängige Variable erstellt. Im nächsten Abschnitt wird die Ausgabe hervorgehoben, die in der Variablenansicht und der Datenansicht von SPSS Statistics nach Ausführung dieses Verfahrens zum Erstellen von Dummy-Variablen erstellt wird.
SPSS Statistics
Ausgabe und Dateneinrichtung in SPSS Statistics nach dem Erstellen von Dummy-Variablen
Nach dem Erstellen Ihrer Dummy-Variablen erstellt SPSS Statistics die folgende Variablenerstellungstabelle in seinem IBM SPSS Statistics Viewer:
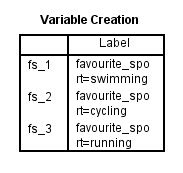
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Die Tabelle der Variablenerstellung bestätigt, dass Sie erfolgreich Dummy-Variablen erstellt haben. Es sollten so viele Zeilen vorhanden sein, wie es neue Dummy-Variablen gibt. Da wir drei Dummy-Variablen erstellt haben, gibt es drei Zeilen in der Tabelle, „fs_1“, „fs_2“ und „fs_3“, die den Stammnamen und die fortlaufende Nummerierung widerspiegeln, die in Schritt 2 des Verfahrens zum Erstellen von Dummy-Variablen im vorherigen Abschnitt eingegeben wurden. Für jede dieser Dummy-Variablen wird in der Tabelle eine Bezeichnung angegeben, um zu verdeutlichen, welche Kategorie der kategorialen unabhängigen Variable die jeweilige Dummy-Variable darstellt. Beispielsweise wird für „fs_1“ die Beschriftung „favourite_sport=swimming“ angegeben, was bedeutet, dass „fs_1“ die Dummy-Variable für die Kategorie „swimming“ der kategorialen unabhängigen Variablen „favourite_sport“ ist.
Als Nächstes wechseln Sie zum Fenster „Variable View“ von SPSS Statistics, indem Sie auf die Registerkarte ![]() klicken. Die drei Dummy-Variablen wurden hinzugefügt, wie unten gezeigt (d. h. die Dummy-Variablen „fs_1“, „fs_2“ und „fs_3“ in der Spalte
klicken. Die drei Dummy-Variablen wurden hinzugefügt, wie unten gezeigt (d. h. die Dummy-Variablen „fs_1“, „fs_2“ und „fs_3“ in der Spalte ![]() ):
):
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis: Sie können die Namen der Dummy-Variablen in der Spalte ![]() ändern, um sie klarer zu kennzeichnen. Zum Beispiel haben wir „fs_1“ in „Schwimmen“, „fs_2“ in „Radfahren“ und „fs_3“ in „Laufen“ geändert, wie unten gezeigt:
ändern, um sie klarer zu kennzeichnen. Zum Beispiel haben wir „fs_1“ in „Schwimmen“, „fs_2“ in „Radfahren“ und „fs_3“ in „Laufen“ geändert, wie unten gezeigt:
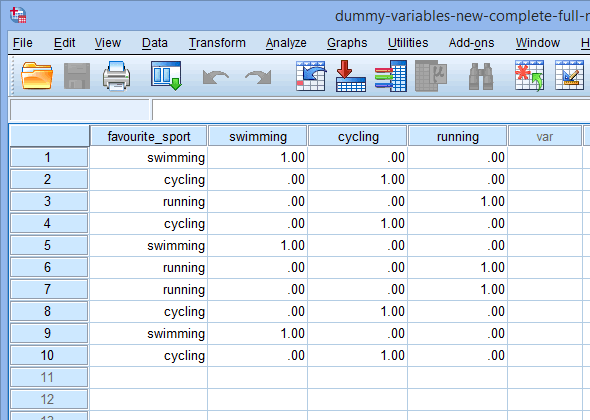
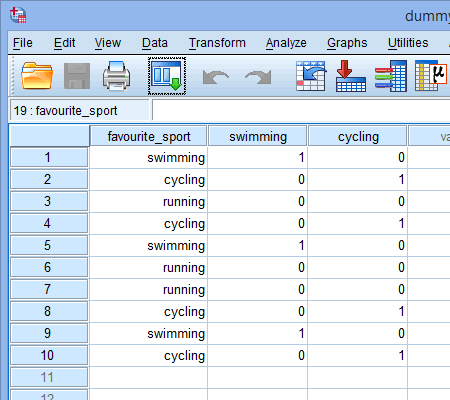
Schließlich gehen Sie zum Fenster Datenansicht von SPSS Statistics, indem Sie auf die Registerkarte ![]() klicken. Die Dummy-Kodierung wird unter jeder der erstellten Dummy-Variablen angezeigt. Zum Beispiel ist in den Zeilen unter der Spalte „fs_1“ die Kategorie „Schwimmen“ mit „1.00“ kodiert, während die Kategorien „Radfahren“ und „Laufen“ mit „.00“ kodiert sind, wie unten gezeigt. Wenn Sie sich nicht sicher sind, warum diese Dummy-Variablen auf diese Weise kodiert sind, lesen Sie den Abschnitt: Verständnis von Dummy-Variablen und Dummy-Codierung.
klicken. Die Dummy-Kodierung wird unter jeder der erstellten Dummy-Variablen angezeigt. Zum Beispiel ist in den Zeilen unter der Spalte „fs_1“ die Kategorie „Schwimmen“ mit „1.00“ kodiert, während die Kategorien „Radfahren“ und „Laufen“ mit „.00“ kodiert sind, wie unten gezeigt. Wenn Sie sich nicht sicher sind, warum diese Dummy-Variablen auf diese Weise kodiert sind, lesen Sie den Abschnitt: Verständnis von Dummy-Variablen und Dummy-Codierung.
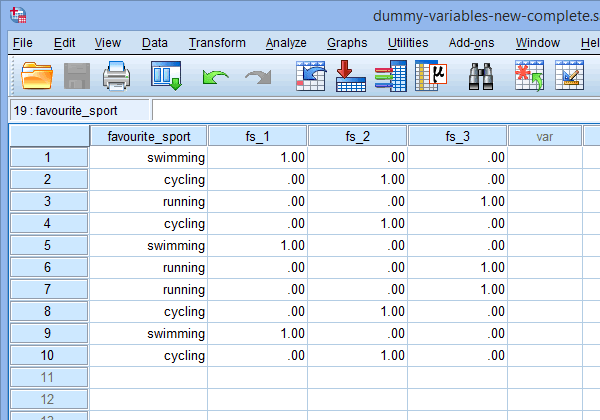
Veröffentlicht mit schriftlicher Genehmigung von SPSS Statistics, IBM Corporation.
Hinweis 1: Aufgrund der Standardeinstellungen von SPSS Statistics werden Ihre Dummy-Variablen mit „1.00“ oder „.00“ anstelle von „1“ bzw. „0“ codiert. Sie sind identisch. Sie werden jedoch häufig sehen, dass die Dummy-Kodierung in Form von 1en und 0en geschrieben wird, anstatt Dezimalzahlen einzuschließen.
Hinweis 2: Wenn Sie die Namen der Dummy-Variablen in der Spalte ![]() des obigen Fensters „Variablenansicht“ geändert haben, wurden diese auch in den Spalten des Fensters „Datenansicht“ geändert, wie im Folgenden gezeigt wird (z. B. heißt die Spaltenüberschrift
des obigen Fensters „Variablenansicht“ geändert haben, wurden diese auch in den Spalten des Fensters „Datenansicht“ geändert, wie im Folgenden gezeigt wird (z. B. heißt die Spaltenüberschrift ![]() jetzt
jetzt ![]() ):
):