Overview
- Lernen Sie Bias und Varianz in einem gegebenen Modell zu interpretieren.
- Was ist der Unterschied zwischen Bias und Varianz?
- Wie erreicht man den Bias- und Varianz-Tradeoff mit Hilfe von Machine Learning Workflow
Einführung
Lassen Sie uns über das Wetter sprechen. Es regnet nur, wenn es ein wenig feucht ist, und es regnet nicht, wenn es windig, heiß oder kalt ist. Wie würden Sie in diesem Fall ein Vorhersagemodell trainieren und sicherstellen, dass die Wettervorhersage keine Fehler enthält? Sie werden vielleicht sagen, dass es viele Lernalgorithmen gibt, aus denen man wählen kann. Sie unterscheiden sich in vielerlei Hinsicht, aber es gibt einen großen Unterschied zwischen dem, was wir erwarten, und dem, was das Modell vorhersagt. Das ist das Konzept von Bias und Variance Tradeoff.
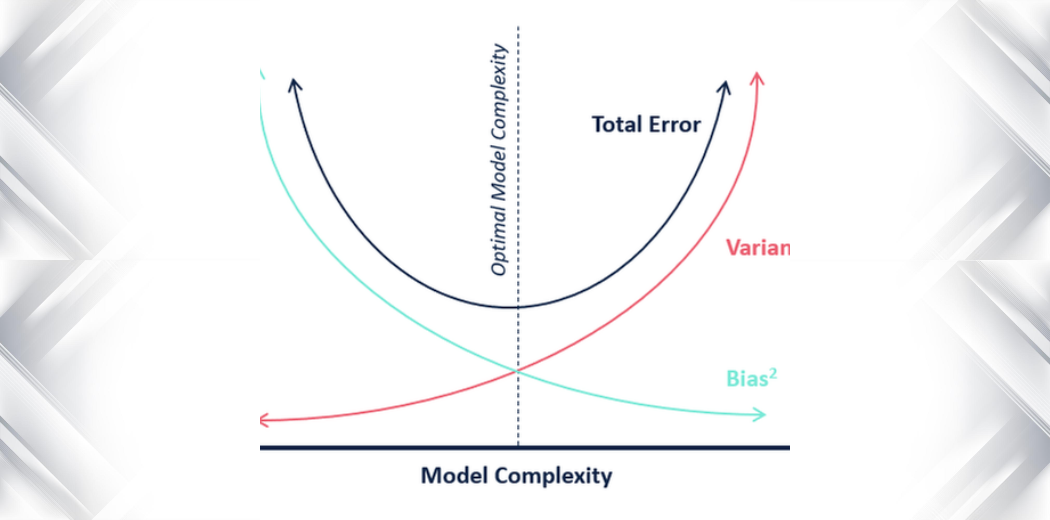
Gewöhnlich werden Bias und Variance Tradeoff durch dichte mathematische Formeln vermittelt. In diesem Artikel habe ich jedoch versucht, Bias und Varianz so einfach wie möglich zu erklären!
Mein Hauptaugenmerk wird darauf liegen, Sie durch den Prozess des Verstehens der Problemstellung zu führen und sicherzustellen, dass Sie das beste Modell wählen, bei dem die Bias- und Varianzfehler minimal sind.
Dazu habe ich den beliebten Pima-Indianer-Diabetes-Datensatz herangezogen. Der Datensatz besteht aus Diagnosemessungen von erwachsenen weiblichen Patienten indianischer Abstammung (Pima). Bei diesem Datensatz konzentrieren wir uns auf die Variable „Ergebnis“, die angibt, ob der Patient Diabetes hat oder nicht. Offensichtlich handelt es sich hier um ein binäres Klassifizierungsproblem, und wir werden gleich eintauchen und lernen, wie man es angeht.
Wenn Sie sich für diese und andere Konzepte der Datenwissenschaft interessieren und praktisch lernen wollen, lesen Sie unseren Kurs – Einführung in die Datenwissenschaft
Inhaltsverzeichnis
- Evaluieren eines Modells für maschinelles Lernen
- Problemstellung und erste Schritte
- Was ist Bias?
- Was ist Varianz?
- Bias-Varianz-Abgleich
Evaluieren Sie Ihr Machine Learning Modell
Das primäre Ziel des Machine Learning Modells ist es, aus den gegebenen Daten zu lernen und Vorhersagen auf der Grundlage der während des Lernprozesses beobachteten Muster zu erstellen. Doch damit ist unsere Aufgabe noch nicht beendet. Wir müssen die Modelle auf der Grundlage der Ergebnisse, die sie liefern, kontinuierlich verbessern. Außerdem quantifizieren wir die Leistung des Modells anhand von Kennzahlen wie Genauigkeit, mittleres Fehlerquadrat (MSE), F1-Score usw. und versuchen, diese Kennzahlen zu verbessern. Dies kann oft schwierig werden, wenn wir die Flexibilität des Modells beibehalten müssen, ohne seine Korrektheit zu beeinträchtigen.
Ein überwachtes Modell für maschinelles Lernen zielt darauf ab, sich selbst auf die Eingabevariablen (X) so zu trainieren, dass die vorhergesagten Werte (Y) den tatsächlichen Werten so nahe wie möglich kommen. Die Differenz zwischen den tatsächlichen Werten und den vorhergesagten Werten ist der Fehler, der zur Bewertung des Modells herangezogen wird. Der Fehler für jeden überwachten Algorithmus des maschinellen Lernens besteht aus 3 Teilen:
- Bias-Fehler
- Varianz-Fehler
- Das Rauschen
Während das Rauschen der irreduzible Fehler ist, den wir nicht eliminieren können, sind die anderen beiden d. h.
In den folgenden Abschnitten werden wir den Bias-Fehler, den Varianz-Fehler und den Bias-Varianz-Kompromiss behandeln, die uns bei der Auswahl des besten Modells helfen werden. Und das Spannende ist, dass wir einige Techniken zum Umgang mit diesen Fehlern anhand eines Beispieldatensatzes behandeln werden.
Problemstellung und primäre Schritte
Wie bereits erläutert, haben wir den Pima-Indianer-Diabetes-Datensatz aufgegriffen und ein Klassifizierungsproblem darauf aufgebaut. Beginnen wir damit, den Datensatz zu vermessen und zu sehen, mit welcher Art von Daten wir es zu tun haben. Dazu importieren wir die erforderlichen Bibliotheken:
Nun laden wir die Daten in einen Datenrahmen und betrachten einige Zeilen, um einen Einblick in die Daten zu erhalten.
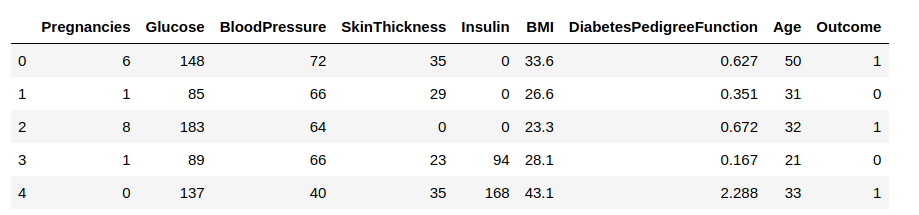
Wir müssen die Spalte „Outcome“ vorhersagen. Trennen wir sie ab und ordnen sie einer Zielvariablen ‚y‘ zu. Der Rest des Datenrahmens wird die Menge der Eingabevariablen X sein.
Skalieren wir nun die Prädiktorvariablen und trennen dann die Trainings- und Testdaten.
Da die Ergebnisse in binärer Form klassifiziert werden, werden wir den einfachsten K-Nächste-Nachbar-Klassifikator (Knn) verwenden, um zu klassifizieren, ob der Patient Diabetes hat oder nicht.
Wie entscheiden wir jedoch den Wert von ‚k‘?
- Vielleicht sollten wir k = 1 verwenden, damit wir sehr gute Ergebnisse für unsere Trainingsdaten erhalten? Das könnte funktionieren, aber wir können nicht garantieren, dass das Modell bei unseren Testdaten genauso gut abschneidet, da es zu spezifisch werden kann
- Wie wäre es, wenn wir einen hohen Wert von k verwenden, z. B. k = 100, so dass wir eine große Anzahl nächstgelegener Punkte berücksichtigen können, um auch die entfernten Punkte zu berücksichtigen? Ein solches Modell ist jedoch zu allgemein und wir können nicht sicher sein, dass es alle möglichen Merkmale korrekt berücksichtigt hat.
Wir nehmen einige mögliche Werte von k und passen das Modell an die Trainingsdaten für alle diese Werte an. Wir werden auch die Trainings- und Testwerte für alle diese Werte berechnen.
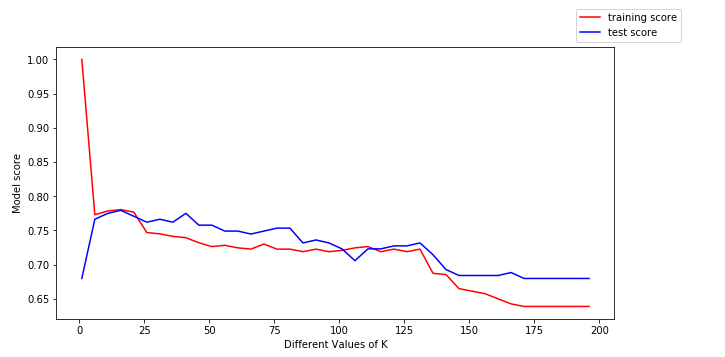
Um weitere Erkenntnisse daraus zu gewinnen, stellen wir die Trainingsdaten (in rot) und die Testdaten (in blau) dar.
Um die Werte für einen bestimmten Wert von k zu berechnen,
![]()
können wir aus dem obigen Diagramm die folgenden Schlüsse ziehen:
- Für niedrige Werte von k ist der Trainingswert hoch, während der Testwert niedrig ist
- Wenn der Wert von k steigt, beginnt der Testwert zu steigen und der Trainingswert zu sinken.
- Bei einem bestimmten Wert von k liegen jedoch sowohl der Trainingswert als auch der Testwert nahe beieinander.
Hier kommen Bias und Varianz ins Spiel.
Was ist Bias?
In den einfachsten Worten ist Bias die Differenz zwischen dem vorhergesagten Wert und dem erwarteten Wert. Zur weiteren Erläuterung: Das Modell geht von bestimmten Annahmen aus, wenn es auf den bereitgestellten Daten trainiert. Wenn es auf die Test-/Validierungsdaten angewendet wird, sind diese Annahmen möglicherweise nicht immer korrekt.
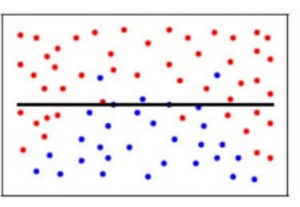
Wenn wir in unserem Modell eine große Anzahl von nächsten Nachbarn verwenden, kann das Modell durchaus entscheiden, dass einige Parameter überhaupt nicht wichtig sind. Es kann zum Beispiel einfach davon ausgehen, dass der Blutzuckerspiegel und der Blutdruck darüber entscheiden, ob der Patient Diabetes hat. Dieses Modell würde sehr starke Annahmen darüber treffen, dass die anderen Parameter keinen Einfluss auf das Ergebnis haben. Man kann es sich auch als ein Modell vorstellen, das eine einfache Beziehung vorhersagt, obwohl die Datenpunkte eindeutig auf eine komplexere Beziehung hindeuten:
Mathematisch gesehen seien die Eingangsvariablen X und eine Zielvariable Y. Wir bilden die Beziehung zwischen den beiden mithilfe einer Funktion f ab.
Daher gilt,
Y = f(X) + e
Hier ist ‚e‘ der normalverteilte Fehler. Das Ziel unseres Modells f'(x) ist es, Werte vorherzusagen, die so nah wie möglich an f(x) liegen. Hier ist der Bias des Modells:
Bias = E
Wie ich oben erklärt habe, führt das Modell, wenn es Verallgemeinerungen vornimmt, d.h. wenn es einen hohen Bias-Fehler gibt, zu einem sehr vereinfachten Modell, das die Variationen nicht sehr gut berücksichtigt. Da es die Trainingsdaten nicht sehr gut lernt, nennt man dies Underfitting.
Was ist eine Varianz?
Im Gegensatz zum Bias berücksichtigt das Modell bei der Varianz auch die Schwankungen in den Daten, d.h. das Rauschen. Was passiert also, wenn unser Modell eine hohe Varianz hat?
Das Modell wird die Varianz immer noch als etwas betrachten, aus dem es lernen kann. Das heißt, das Modell lernt zu viel aus den Trainingsdaten, und zwar so viel, dass es, wenn es mit neuen (Test-)Daten konfrontiert wird, nicht in der Lage ist, auf der Grundlage dieser Daten genaue Vorhersagen zu treffen.
Mathematisch gesehen ist der Varianzfehler im Modell:
Varianz-E^2
Da das Modell im Falle einer hohen Varianz zu viel aus den Trainingsdaten lernt, nennt man dies Overfitting.
Wenn wir im Zusammenhang mit unseren Daten nur sehr wenige nächste Nachbarn verwenden, ist das so, als ob wir sagen würden, dass der Patient Diabetes hat, wenn die Anzahl der Schwangerschaften mehr als 3 beträgt, der Blutzuckerspiegel mehr als 78 beträgt, der diastolische Blutdruck weniger als 98 beträgt, die Hautdicke weniger als 23 mm beträgt und so weiter für jedes Merkmal…… Alle anderen Patienten, die die oben genannten Kriterien nicht erfüllen, sind nicht diabetisch. Dies mag zwar für einen bestimmten Patienten in der Trainingsgruppe zutreffen, was aber, wenn diese Parameter die Ausreißer sind oder sogar falsch erfasst wurden? Ein solches Modell könnte sich als sehr kostspielig erweisen!
Außerdem hätte dieses Modell eine hohe Fehlervarianz, da die Vorhersagen, ob ein Patient zuckerkrank ist oder nicht, je nach Art der Trainingsdaten, die wir ihm zur Verfügung stellen, stark variieren. So würde selbst eine Änderung des Blutzuckerspiegels auf 75 dazu führen, dass das Modell vorhersagt, dass der Patient keinen Diabetes hat.
Zur Vereinfachung sagt das Modell sehr komplexe Beziehungen zwischen dem Ergebnis und den Eingabemerkmalen voraus, obwohl eine quadratische Gleichung ausgereicht hätte. So sieht ein Klassifizierungsmodell aus, wenn es eine hohe Fehlervarianz bzw. eine Überanpassung gibt:
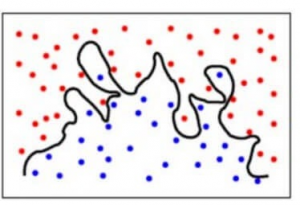
Zusammengefasst,
- Ein Modell mit einem hohen Bias-Fehler passt sich nicht an die Daten an und trifft sehr einfache Annahmen
- Ein Modell mit einem hohen Varianzfehler passt sich nicht an die Daten an und lernt zu viel aus ihnen
- Ein gutes Modell ist ein Modell, bei dem sowohl Bias- als auch Varianzfehler ausgeglichen sind
Bias-Variance Tradeoff
Wie lassen sich die oben genannten Konzepte auf unser Knn-Modell von vorhin beziehen? Finden wir es heraus!
In unserem Modell wird beispielsweise für k = 1 der Punkt berücksichtigt, der dem fraglichen Datenpunkt am nächsten liegt. In diesem Fall könnte die Vorhersage für diesen bestimmten Datenpunkt genau sein, so dass der Verzerrungsfehler geringer ist.
Der Varianzfehler wird jedoch hoch sein, da nur der nächstgelegene Punkt berücksichtigt wird und die anderen möglichen Punkte nicht in Betracht gezogen werden. Welchem Szenario entspricht dies Ihrer Meinung nach? Ja, Sie denken richtig, das bedeutet, dass unser Modell überangepasst ist.
Andererseits werden bei höheren Werten von k viel mehr Punkte berücksichtigt, die näher am betreffenden Datenpunkt liegen. Dies würde zu einem höheren Bias-Fehler und einer Unteranpassung führen, da viele Punkte, die näher am Datenpunkt liegen, berücksichtigt werden und das Modell somit nicht die Besonderheiten aus dem Trainingssatz lernen kann. Wir können jedoch einen niedrigeren Varianzfehler für den Testsatz berücksichtigen, der unbekannte Werte hat.
Um ein Gleichgewicht zwischen dem Bias-Fehler und dem Varianzfehler zu erreichen, brauchen wir einen solchen Wert von k, dass das Modell weder aus dem Rauschen lernt (Überanpassung der Daten) noch pauschale Annahmen über die Daten macht (Unteranpassung der Daten). Um es einfacher zu halten, würde ein ausgewogenes Modell wie folgt aussehen:
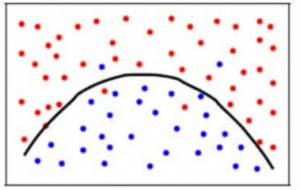
Obwohl einige Punkte falsch klassifiziert werden, passt das Modell im Allgemeinen für die meisten Datenpunkte genau. Das Gleichgewicht zwischen dem Bias-Fehler und dem Varianzfehler ist der Bias-Varianz-Tradeoff.
Das folgende Bullenaugen-Diagramm erklärt den Tradeoff besser:
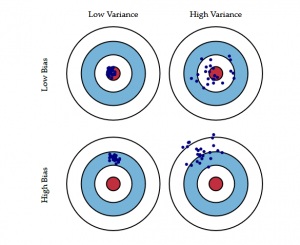
Die Mitte, d.h. das Bullenauge, ist das angestrebte Modellergebnis, das alle Werte korrekt vorhersagt. Je weiter wir uns von der Mitte entfernen, desto mehr falsche Vorhersagen macht unser Modell.
Ein Modell mit geringer Verzerrung und hoher Varianz sagt Punkte voraus, die im Allgemeinen um die Mitte herum liegen, aber ziemlich weit voneinander entfernt sind. Ein Modell mit hoher Verzerrung und geringer Varianz ist ziemlich weit vom Zentrum entfernt, aber da die Varianz gering ist, liegen die vorhergesagten Punkte näher beieinander.
In Bezug auf die Modellkomplexität können wir das folgende Diagramm verwenden, um über die optimale Komplexität unseres Modells zu entscheiden.
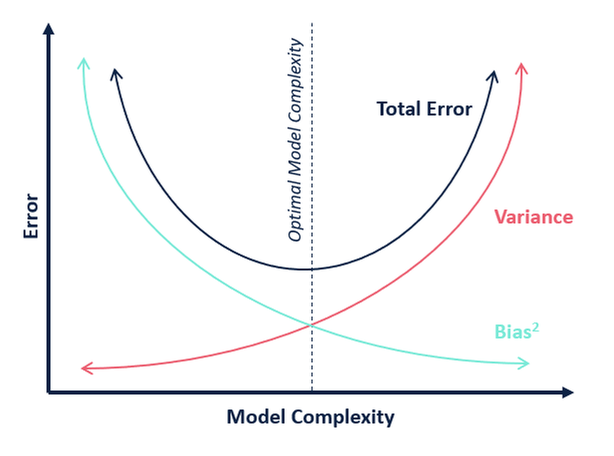
Was ist Ihrer Meinung nach der optimale Wert für k?
Aus der obigen Erklärung können wir schließen, dass das k, für das
- die Testpunktzahl am höchsten ist und
- beide, die Testpunktzahl und die Trainingspunktzahl, nahe beieinander liegen
der optimale Wert für k ist. Obwohl wir also einen niedrigeren Trainingswert in Kauf nehmen, erhalten wir immer noch einen hohen Wert für unsere Testdaten, was entscheidend ist – die Testdaten sind schließlich unbekannte Daten.
Lassen Sie uns eine Tabelle für verschiedene Werte von k erstellen, um dies weiter zu beweisen:
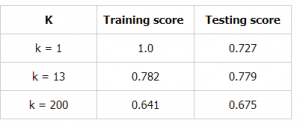
Schlussfolgerung
Zusammenfassend haben wir in diesem Artikel gelernt, dass ein ideales Modell eines ist, bei dem sowohl der Verzerrungsfehler als auch der Varianzfehler niedrig sind. Wir sollten jedoch immer ein Modell anstreben, bei dem die Modellbewertung für die Trainingsdaten so nahe wie möglich an der Modellbewertung für die Testdaten liegt.
Hier haben wir herausgefunden, wie wir ein Modell auswählen, das nicht zu komplex ist (hohe Varianz und niedriger Bias), was zu einer Überanpassung führen würde, und auch nicht zu einfach (hoher Bias und niedrige Varianz), was zu einer Unteranpassung führen würde.
Bias und Varianz spielen eine wichtige Rolle bei der Entscheidung, welches Vorhersagemodell zu verwenden ist. Ich hoffe, dieser Artikel hat das Konzept gut erklärt.