Datenverschlüsselung im Ruhezustand ist ein Muss für jedes moderne Internet-Unternehmen. Viele Unternehmen verschlüsseln ihre Festplatten jedoch nicht, weil sie die möglichen Leistungseinbußen fürchten, die durch den Verschlüsselungs-Overhead verursacht werden.
Die Verschlüsselung von Daten im Ruhezustand ist für Cloudflare mit mehr als 200 Rechenzentren auf der ganzen Welt lebenswichtig. In diesem Beitrag werden wir die Leistung der Festplattenverschlüsselung unter Linux untersuchen und erklären, wie wir sie für uns und unsere Kunden mindestens zweimal schneller gemacht haben!
Verschlüsselung von Daten im Ruhezustand
Wenn es um die Verschlüsselung von Daten im Ruhezustand geht, gibt es mehrere Möglichkeiten, wie sie in einem modernen Betriebssystem (OS) implementiert werden kann. Die verfügbaren Techniken sind eng mit dem typischen Speicher-Stack des Betriebssystems verbunden. Eine vereinfachte Version des Speicherstapels und der Verschlüsselungslösungen ist im folgenden Diagramm dargestellt:
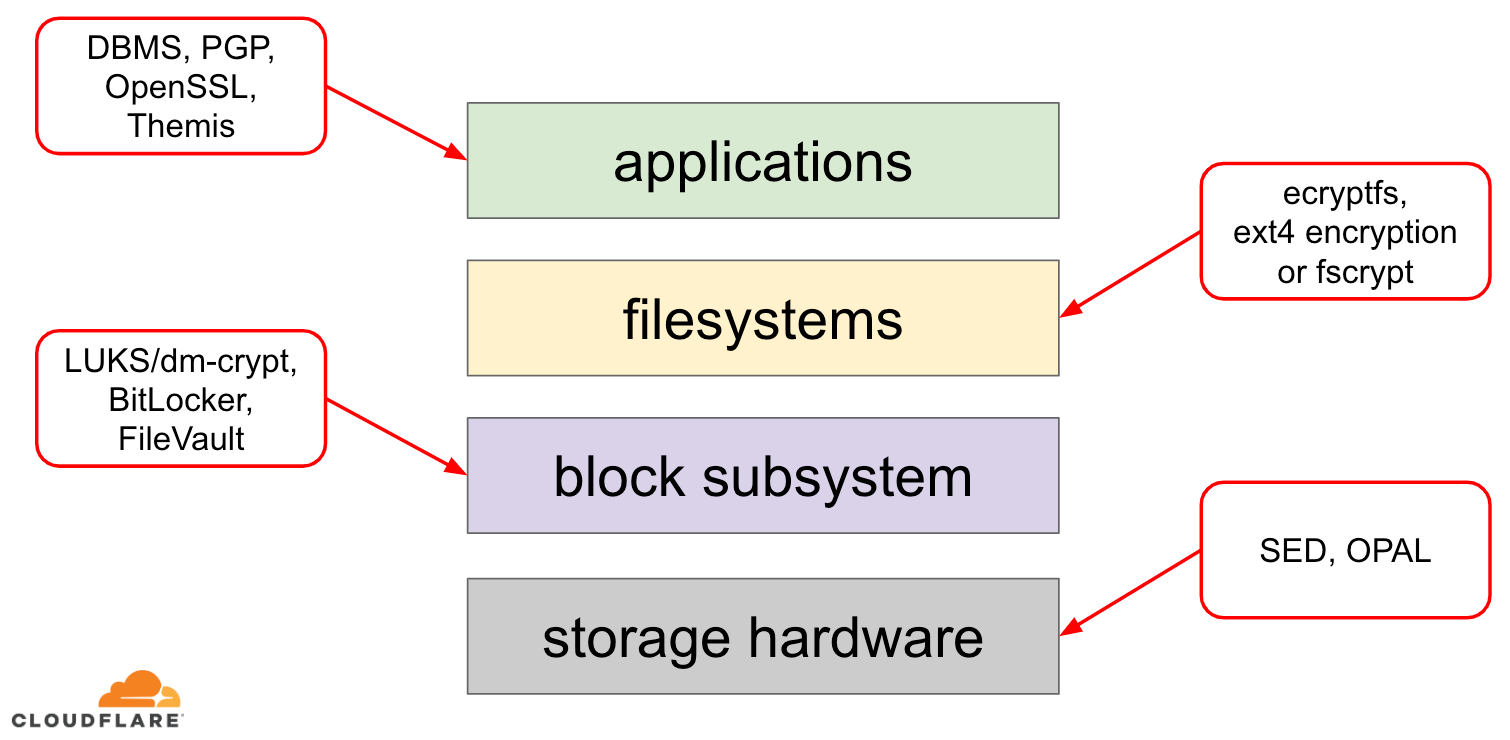
Am oberen Ende des Stapels befinden sich Anwendungen, die Daten in Dateien (oder Streams) lesen und schreiben. Das Dateisystem im Betriebssystemkern verfolgt, welche Blöcke des zugrundeliegenden Blockgeräts zu welchen Dateien gehören und übersetzt diese Dateilese- und -schreibvorgänge in Blocklese- und -schreibvorgänge, wobei die Hardwarespezifika des zugrundeliegenden Speichergeräts vom Dateisystem abstrahiert werden. Schließlich leitet das Block-Subsystem die Blocklese- und -schreibvorgänge mit Hilfe geeigneter Gerätetreiber an die zugrundeliegende Hardware weiter.
Das Konzept des Speicherstapels ähnelt im Grunde dem bekannten OSI-Modell für Netzwerke, bei dem jede Schicht eine übergeordnete Sicht auf die Informationen hat und die Implementierungsdetails der unteren Schichten von den oberen Schichten abstrahiert werden. Und ähnlich wie beim OSI-Modell kann man die Verschlüsselung auf verschiedenen Schichten anwenden (man denke an TLS vs. IPsec oder ein VPN).
Für ruhende Daten kann man die Verschlüsselung entweder auf den Blockschichten (entweder in der Hardware oder in der Software) oder auf der Dateiebene (entweder direkt in den Anwendungen oder im Dateisystem) anwenden.
Block- vs. Dateiverschlüsselung
Im Allgemeinen gilt: Je höher im Stack wir die Verschlüsselung anwenden, desto mehr Flexibilität haben wir. Bei der Verschlüsselung auf Anwendungsebene können die Anwendungsbetreuer jeden beliebigen Verschlüsselungscode auf bestimmte Daten anwenden, die sie benötigen. Der Nachteil dieses Ansatzes besteht darin, dass sie ihn selbst implementieren müssen, und Verschlüsselung ist im Allgemeinen nicht sehr entwicklerfreundlich: Man muss sich mit einem bestimmten kryptografischen Algorithmus auskennen, Schlüssel, Nonces, IVs usw. ordnungsgemäß erzeugen. Außerdem nutzt die Verschlüsselung auf Anwendungsebene das Caching auf Betriebssystemebene und insbesondere den Linux-Seitencache nicht: Jedes Mal, wenn die Anwendung die Daten verwenden muss, muss sie sie entweder erneut entschlüsseln, was CPU-Zyklen verschwendet, oder einen eigenen entschlüsselten „Cache“ implementieren, was den Code noch komplexer macht.
Die Verschlüsselung auf Dateisystemebene macht die Datenverschlüsselung für Anwendungen transparent, da das Dateisystem selbst die Daten verschlüsselt, bevor es sie an das Block-Subsystem weitergibt, so dass Dateien unabhängig davon verschlüsselt werden, ob die Anwendung Krypto-Unterstützung hat oder nicht. Außerdem können Dateisysteme so konfiguriert werden, dass sie nur ein bestimmtes Verzeichnis verschlüsseln oder verschiedene Schlüssel für verschiedene Dateien haben. Diese Flexibilität wird jedoch durch eine komplexere Konfiguration erkauft. Die Verschlüsselung von Dateisystemen gilt auch als weniger sicher als die Verschlüsselung von Blockgeräten, da nur der Inhalt der Dateien verschlüsselt wird. Dateien haben auch zugehörige Metadaten, wie die Dateigröße, die Anzahl der Dateien, das Layout des Verzeichnisbaums usw., die für einen potenziellen Angreifer immer noch sichtbar sind.
Die Verschlüsselung auf der Blockebene (oft als Festplattenverschlüsselung oder vollständige Festplattenverschlüsselung bezeichnet) macht die Datenverschlüsselung auch für Anwendungen und sogar ganze Dateisysteme transparent. Im Gegensatz zur Verschlüsselung auf Dateisystemebene verschlüsselt sie alle Daten auf der Festplatte, einschließlich der Metadaten und sogar des freien Speicherplatzes. Sie ist jedoch weniger flexibel – man kann nur die gesamte Festplatte mit einem einzigen Schlüssel verschlüsseln, es gibt also keine Konfiguration pro Verzeichnis, pro Datei oder pro Benutzer. Aus kryptografischer Sicht können nicht alle kryptografischen Algorithmen verwendet werden, da die Blockschicht keinen Überblick mehr über die Daten hat und daher jeden Block unabhängig verarbeiten muss. Die meisten gängigen Algorithmen erfordern eine Art von Blockverkettung, um sicher zu sein, und sind daher für die Festplattenverschlüsselung nicht geeignet. Stattdessen wurden spezielle Modi nur für diesen speziellen Anwendungsfall entwickelt.
Welchen Layer soll man also wählen? Wie immer kommt es darauf an… Die Verschlüsselung auf Anwendungs- und Dateisystemebene ist in der Regel die bevorzugte Wahl für Client-Systeme, weil sie flexibel ist. So kann beispielsweise jeder Benutzer eines Mehrbenutzer-Desktops sein Home-Verzeichnis mit einem eigenen Schlüssel verschlüsseln und einige gemeinsam genutzte Verzeichnisse unverschlüsselt lassen. Bei Serversystemen, die von SaaS/PaaS/IaaS-Unternehmen (einschließlich Cloudflare) verwaltet werden, ist die bevorzugte Wahl dagegen die Einfachheit der Konfiguration und die Sicherheit – bei aktivierter vollständiger Festplattenverschlüsselung werden alle Daten von jeder Anwendung automatisch verschlüsselt, ohne Ausnahmen oder Überschreibungen. Wir glauben, dass alle Daten geschützt werden müssen, ohne sie in „wichtig“ oder „unwichtig“ zu sortieren, so dass die selektive Flexibilität, die die oberen Schichten bieten, nicht benötigt wird.
Hardware vs. Software Festplattenverschlüsselung
Wenn Daten auf der Blockschicht verschlüsselt werden, ist es möglich, dies direkt in der Speicherhardware zu tun, wenn die Hardware dies unterstützt. Dies führt in der Regel zu einer besseren Lese-/Schreibleistung und verbraucht weniger Ressourcen auf dem Host. Da die meiste Hardware-Firmware jedoch proprietär ist, wird ihr von der Sicherheitsgemeinschaft nicht so viel Aufmerksamkeit und Überprüfung zuteil. In der Vergangenheit führte dies zu Fehlern in einigen Implementierungen der Hardware-Festplattenverschlüsselung, die das gesamte Sicherheitsmodell unbrauchbar machten. Microsoft beispielsweise bevorzugt seither softwarebasierte Festplattenverschlüsselung.
Wir wollten unsere Daten und die Daten unserer Kunden nicht dem Risiko aussetzen, potenziell unsichere Lösungen zu verwenden, und wir glauben fest an Open-Source. Deshalb setzen wir nur auf Software-Festplattenverschlüsselung im Linux-Kernel, der offen ist und von vielen Sicherheitsexperten auf der ganzen Welt geprüft wurde.
Linux-Festplattenverschlüsselungsleistung
Wir wollen nicht nur Bandbreitenkosten für unsere Kunden sparen, sondern den Internetnutzern Inhalte so schnell wie möglich zur Verfügung stellen.
Zu einem bestimmten Zeitpunkt haben wir festgestellt, dass unsere Festplatten nicht so schnell waren, wie wir es gerne hätten. Einige Profilerstellungen sowie ein schneller A/B-Test wiesen auf die Linux-Festplattenverschlüsselung hin. Da es keine nachhaltige Option ist, die Daten nicht zu verschlüsseln (selbst wenn es sich um einen öffentlichen Internet-Cache handelt), haben wir beschlossen, uns die Leistung der Linux-Festplattenverschlüsselung genauer anzusehen.
Device Mapper und dm-crypt
Linux implementiert die transparente Festplattenverschlüsselung über ein dm-crypt-Modul und dm-crypt ist selbst Teil des Device Mapper-Kernel-Frameworks. Kurz gesagt, der Device Mapper ermöglicht die Vor- und Nachbearbeitung von IO-Anforderungen auf dem Weg zwischen dem Dateisystem und dem zugrunde liegenden Blockgerät.
dm-crypt verschlüsselt insbesondere „schreibende“ IO-Anforderungen, bevor sie weiter unten im Stapel an das eigentliche Blockgerät gesendet werden, und entschlüsselt „lesende“ IO-Anforderungen, bevor sie nach oben an den Dateisystemtreiber gesendet werden. Einfach und leicht! Oder doch?
Benchmarking-Setup
Fürs Protokoll: Die Zahlen in diesem Beitrag wurden durch die Ausführung der angegebenen Befehle auf einem Cloudflare G9-Server im Leerlauf außerhalb der Produktion ermittelt. Das Setup sollte jedoch auf jedem modernen x86-Laptop leicht reproduzierbar sein.
Generell ist es schwierig, Benchmarks mit einem Speicherstapel durchzuführen, da die Speicherhardware selbst Störungen verursacht. Nicht alle Festplatten sind gleich, daher werden wir für diesen Beitrag die schnellsten verfügbaren Festplatten verwenden – also keine Festplatten.
Stattdessen bietet Linux die Möglichkeit, eine Festplatte direkt im RAM zu emulieren. Da der Arbeitsspeicher viel schneller ist als jeder andere dauerhafte Speicher, sollte dies unsere Ergebnisse nur geringfügig beeinflussen.
Der folgende Befehl erstellt eine 4 GB große Ramdisk:
$ sudo modprobe brd rd_nr=1 rd_size=4194304$ ls /dev/ram0Nun können wir eine dm-crypt-Instanz darauf einrichten und so die Verschlüsselung für die Disk aktivieren. Zuerst müssen wir den Schlüssel für die Festplattenverschlüsselung generieren, die Festplatte „formatieren“ und ein Passwort angeben, um den neu generierten Schlüssel zu entsperren.
$ fallocate -l 2M crypthdr.img$ sudo cryptsetup luksFormat /dev/ram0 --header crypthdr.imgWARNING!========This will overwrite data on crypthdr.img irrevocably.Are you sure? (Type uppercase yes): YESEnter passphrase:Verify passphrase:Wer mit LUKS/dm-crypt vertraut ist, hat vielleicht bemerkt, dass wir hier einen LUKS-getrennten Header verwendet haben. Normalerweise speichert LUKS den passwortverschlüsselten Festplattenverschlüsselungsschlüssel auf derselben Festplatte wie die Daten, aber da wir die Lese-/Schreibleistung zwischen verschlüsselten und unverschlüsselten Geräten vergleichen wollen, könnten wir den verschlüsselten Schlüssel während unseres Benchmarkings später versehentlich überschreiben. Indem wir den verschlüsselten Schlüssel in einer separaten Datei aufbewahren, vermeiden wir dieses Problem für die Zwecke dieses Beitrags.
Jetzt können wir das verschlüsselte Gerät für unsere Tests tatsächlich „entsperren“:
$ sudo cryptsetup open --header crypthdr.img /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ ls /dev/mapper/encrypted-ram0/dev/mapper/encrypted-ram0An dieser Stelle können wir nun die Leistung von verschlüsselten und unverschlüsselten Ramdisks vergleichen: Wenn wir Daten auf /dev/ram0 lesen/schreiben, werden sie im Klartext gespeichert. Wenn wir Daten auf /dev/mapper/encrypted-ram0 lesen/schreiben, werden sie auf dem Weg von dm-crypt entschlüsselt/verschlüsselt und in Ciphertext gespeichert.
Es ist erwähnenswert, dass wir kein Dateisystem auf unseren Blockgeräten erstellen, um zu vermeiden, dass die Ergebnisse durch einen Dateisystem-Overhead verzerrt werden.
Messung des Durchsatzes
Wenn es um Speichertests/Benchmarking geht, ist der Flexible I/O-Tester die übliche Lösung für uns. Simulieren wir eine einfache sequentielle Lese-/Schreiblast mit einer Blockgröße von 4K auf der Ramdisk ohne Verschlüsselung:
$ sudo fio --filename=/dev/ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=plainplain: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=21013MB, aggrb=1126.5MB/s, minb=1126.5MB/s, maxb=1126.5MB/s, mint=18655msec, maxt=18655msec WRITE: io=21023MB, aggrb=1126.1MB/s, minb=1126.1MB/s, maxb=1126.1MB/s, mint=18655msec, maxt=18655msecDisk stats (read/write): ram0: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%Der obige Befehl wird lange laufen, also brechen wir ihn nach einer Weile einfach ab. Wie wir aus den Statistiken ersehen können, sind wir in der Lage, mit ungefähr dem gleichen Durchsatz um 1126 MB/s zu lesen und zu schreiben. Wiederholen wir den Test mit der verschlüsselten Ramdisk:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1693.7MB, aggrb=150874KB/s, minb=150874KB/s, maxb=150874KB/s, mint=11491msec, maxt=11491msec WRITE: io=1696.4MB, aggrb=151170KB/s, minb=151170KB/s, maxb=151170KB/s, mint=11491msec, maxt=11491msecWhoa, das ist ein Einbruch! Wir erhalten nur noch ~147 MB/s, was mehr als 7 mal langsamer ist! Und das auf einem völlig untätigen Rechner!
Vielleicht ist Crypto einfach nur langsam
Das erste, was wir bedacht haben, ist sicherzustellen, dass wir das schnellste Crypto verwenden. cryptsetup ermöglicht es uns, alle verfügbaren Krypto-Implementierungen auf dem System zu vergleichen, um die beste auszuwählen:
$ sudo cryptsetup benchmark# Tests are approximate using memory only (no storage IO).PBKDF2-sha1 1340890 iterations per second for 256-bit keyPBKDF2-sha256 1539759 iterations per second for 256-bit keyPBKDF2-sha512 1205259 iterations per second for 256-bit keyPBKDF2-ripemd160 967321 iterations per second for 256-bit keyPBKDF2-whirlpool 720175 iterations per second for 256-bit key# Algorithm | Key | Encryption | Decryption aes-cbc 128b 969.7 MiB/s 3110.0 MiB/s serpent-cbc 128b N/A N/A twofish-cbc 128b N/A N/A aes-cbc 256b 756.1 MiB/s 2474.7 MiB/s serpent-cbc 256b N/A N/A twofish-cbc 256b N/A N/A aes-xts 256b 1823.1 MiB/s 1900.3 MiB/s serpent-xts 256b N/A N/A twofish-xts 256b N/A N/A aes-xts 512b 1724.4 MiB/s 1765.8 MiB/s serpent-xts 512b N/A N/A twofish-xts 512b N/A N/AEs scheint, dass aes-xts mit einem 256-Bit-Datenverschlüsselungsschlüssel hier am schnellsten ist. Aber welche verwenden wir eigentlich für unsere verschlüsselte Ramdisk?
$ sudo dmsetup table /dev/mapper/encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0Wir verwenden aes-xts mit einem 256-Bit-Datenverschlüsselungsschlüssel (zählen Sie alle Nullen, die das Werkzeug dmsetup maskiert – wenn Sie die tatsächlichen Bytes sehen wollen, fügen Sie dem obigen Befehl die Option --showkeys hinzu). Die Zahlen addieren sich jedoch nicht: cryptsetup benchmark sagt uns oben, dass wir uns nicht auf die Ergebnisse verlassen sollen, da „die Tests nur annähernd den Arbeitsspeicher verwenden (keine Speicher-IO)“, aber genau so haben wir unser Experiment mit der Ramdisk aufgebaut. In einem etwas schlechteren Fall (unter der Annahme, dass wir alle Daten lesen und sie dann sequentiell und ohne Parallelität ver- und entschlüsseln) sollten wir bei einer Rückwärtsberechnung etwa (1126 * 1823) / (1126 + 1823) =~696 MB/s erhalten, was immer noch ziemlich weit von den tatsächlichen 147 * 2 = 294 MB/s (Summe aus Lese- und Schreibvorgängen) entfernt ist.
dm-crypt performance flags
Beim Lesen der cryptsetup man page ist uns aufgefallen, dass es zwei Optionen mit dem Präfix --perf- gibt, die wahrscheinlich mit der Leistungsoptimierung zu tun haben. Die erste ist --perf-same_cpu_crypt mit einer ziemlich kryptischen Beschreibung:
Perform encryption using the same cpu that IO was submitted on. The default is to use an unbound workqueue so that encryption work is automatically balanced between available CPUs. This option is only relevant for open action.Also aktivieren wir die Option
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-same_cpu_crypt /dev/ram0 encrypted-ram0Anmerkung: laut der neuesten Manpage gibt es auch einen cryptsetup refresh Befehl, mit dem man diese Optionen live aktivieren kann, ohne das verschlüsselte Gerät „schließen“ und „wieder öffnen“ zu müssen. Unser cryptsetup unterstützte dies jedoch noch nicht.
Überprüfen, ob die Option wirklich aktiviert wurde:
$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 same_cpu_cryptJa, wir können nun same_cpu_crypt in der Ausgabe sehen, was wir wollten. Führen wir den Benchmark erneut aus:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=1596.6MB, aggrb=139811KB/s, minb=139811KB/s, maxb=139811KB/s, mint=11693msec, maxt=11693msec WRITE: io=1600.9MB, aggrb=140192KB/s, minb=140192KB/s, maxb=140192KB/s, mint=11693msec, maxt=11693msecHmm, jetzt ist es ~136 MB/s, was etwas schlechter ist als vorher, also nicht gut. Was ist mit der zweiten Option --perf-submit_from_crypt_cpus:
Disable offloading writes to a separate thread after encryption. There are some situations where offloading write bios from the encryption threads to a single thread degrades performance significantly. The default is to offload write bios to the same thread. This option is only relevant for open action.Vielleicht sind wir hier in einer „gewissen Situation“, also probieren wir es aus:
$ sudo cryptsetup close encrypted-ram0$ sudo cryptsetup open --header crypthdr.img --perf-submit_from_crypt_cpus /dev/ram0 encrypted-ram0Enter passphrase for /dev/ram0:$ sudo dmsetup table encrypted-ram00 8388608 crypt aes-xts-plain64 0000000000000000000000000000000000000000000000000000000000000000 0 1:0 0 1 submit_from_crypt_cpusUnd jetzt der Benchmark:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Run status group 0 (all jobs): READ: io=2066.6MB, aggrb=169835KB/s, minb=169835KB/s, maxb=169835KB/s, mint=12457msec, maxt=12457msec WRITE: io=2067.7MB, aggrb=169965KB/s, minb=169965KB/s, maxb=169965KB/s, mint=12457msec, maxt=12457msec~166 MB/s, der etwas besser ist, aber immer noch nicht gut…
Fragen an die Community
In unserer Verzweiflung beschlossen wir, im Internet nach Unterstützung zu suchen und schickten unsere Ergebnisse an die dm-crypt Mailingliste, aber die Antwort, die wir bekamen, war nicht sehr ermutigend:
Wenn die Zahlen Sie beunruhigen, dann liegt das an mangelndem Verständnis auf Ihrer Seite. Sie sind sich wahrscheinlich nicht bewusst, dass Verschlüsselung ein schwerwiegender Vorgang ist…
Wir beschlossen, eine wissenschaftliche Untersuchung zu diesem Thema durchzuführen, indem wir „ist Verschlüsselung teuer“ in die Google-Suche eingaben, und eines der Top-Ergebnisse, das tatsächlich aussagekräftige Messungen enthält, ist… unser eigener Beitrag über die Kosten der Verschlüsselung, aber im Zusammenhang mit TLS! Das ist schon für sich genommen eine faszinierende Lektüre, aber die Quintessenz ist: Moderne Verschlüsselung auf moderner Hardware ist selbst im Cloudflare-Maßstab (Millionen von verschlüsselten HTTP-Anfragen pro Sekunde) sehr günstig. Sie ist sogar so billig, dass Cloudflare der erste Anbieter war, der kostenloses SSL/TLS für alle anbot.
Ein Blick in den Quellcode
Als wir versuchten, die oben beschriebenen benutzerdefinierten dm-crypt-Optionen zu verwenden, waren wir neugierig, warum es sie überhaupt gibt und was es mit dem „Offloading“ auf sich hat. Ursprünglich hatten wir erwartet, dass dm-crypt ein einfacher „Proxy“ ist, der Daten verschlüsselt/entschlüsselt, während sie den Stack durchlaufen. Es stellte sich heraus, dass dm-crypt mehr tut, als nur Speicherpuffer zu verschlüsseln, und ein (vereinfachtes) IO-Traverse-Pfad-Diagramm ist unten dargestellt:

Wenn das Dateisystem eine Schreibanforderung ausgibt, verarbeitet dm-crypt diese nicht sofort – stattdessen legt es sie in eine Workqueue namens „kcryptd“. Kurz gesagt, eine Kernel-Workqueue plant einfach eine Arbeit (in diesem Fall Verschlüsselung) für einen späteren Zeitpunkt, wenn es günstiger ist. Wenn „die Zeit“ gekommen ist, sendet dm-crypt die Anfrage an Linux Crypto API für die tatsächliche Verschlüsselung. Allerdings ist die moderne Linux Crypto API auch asynchron, so dass die Anfrage, je nachdem, welche Implementierung Ihr System verwendet, höchstwahrscheinlich nicht sofort verarbeitet wird, sondern in eine Warteschlange für einen „späteren Zeitpunkt“ gestellt wird. Wenn Linux Crypto API schließlich die Verschlüsselung durchführt, kann dm-crypt versuchen, die ausstehenden Schreibanforderungen zu sortieren, indem er jede Anforderung in einen rot-schwarzen Baum stellt. Dann nimmt ein separater Kernel-Thread „irgendwann später“ alle IO-Anforderungen im Baum und schickt sie den Stapel hinunter.
Nun zu den Leseanforderungen: Diesmal müssen wir die verschlüsselten Daten zuerst von der Hardware bekommen, aber dm-crypt fragt nicht einfach nach dem Treiber für die Daten, sondern stellt die Anforderung in eine andere Workqueue namens „kcryptd_io“. Zu einem späteren Zeitpunkt, wenn wir die verschlüsselten Daten tatsächlich haben, planen wir sie für die Entschlüsselung mit der nun bekannten „kcryptd“-Workqueue. „kcryptd“ sendet die Anfrage an die Linux Crypto API, die die Daten auch asynchron entschlüsseln kann.
Fairerweise durchläuft die Anfrage nicht immer alle diese Warteschlangen, aber der wichtige Teil hier ist, dass Schreibanfragen bis zu viermal in dm-crypt und Leseanfragen bis zu dreimal in die Warteschlange gestellt werden können. An diesem Punkt haben wir uns gefragt, ob diese zusätzliche Warteschlangenbildung zu Leistungsproblemen führen kann. Es gibt zum Beispiel eine schöne Präsentation von Google über die Beziehung zwischen Warteschlangenbildung und Latenzzeit. Eine wichtige Erkenntnis aus der Präsentation ist:
Ein signifikanter Anteil der Tail-Latenz ist auf Warteschlangeneffekte zurückzuführen
Warum sind also all diese Warteschlangen da und können wir sie entfernen?
Git-Archäologie
Niemand schreibt komplexeren Code nur zum Spaß, besonders nicht für den Betriebssystemkern. Also müssen all diese Warteschlangen aus einem bestimmten Grund dort angelegt worden sein. Glücklicherweise wird der Linux-Kernel-Quellcode von git verwaltet, so dass wir versuchen können, die Änderungen und die damit verbundenen Entscheidungen nachzuvollziehen.
Die „kcryptd“-Workqueue war seit Beginn der verfügbaren Historie mit folgendem Kommentar im Quellcode enthalten:
Nötig, weil es sehr unklug wäre, die Entschlüsselung in einem Interrupt-Kontext durchzuführen, so dass Bios, das von Leseanforderungen zurückkehrt, hier in eine Warteschlange gestellt wird.
So war es nur für Leseanfragen, aber selbst dann – warum interessiert es uns, ob es im Interrupt-Kontext ist oder nicht, wenn Linux Crypto API wahrscheinlich sowieso einen eigenen Thread/Warteschlange für die Verschlüsselung verwendet? Nun, 2005 war die Crypto API nicht asynchron, also machte dies durchaus Sinn.
Im Jahr 2006 begann dm-crypt die „kcryptd“-Workqueue nicht nur für die Verschlüsselung zu verwenden, sondern auch für die Übermittlung von IO-Anfragen:
Dieser Patch soll dm-crypt dabei helfen, die neuen Einschränkungen zu erfüllen, die durch den folgenden Patch in -mm auferlegt wurden: md-dm-reduce-stack-usage-with-stacked-block-devices.patch
Es scheint, dass das Ziel hier nicht war, mehr Gleichzeitigkeit hinzuzufügen, sondern eher die Kernel-Stack-Nutzung zu reduzieren, was wiederum Sinn macht, da der Kernel einen gemeinsamen Stack für den gesamten Code hat, also eine ziemlich begrenzte Ressource ist. Es ist jedoch erwähnenswert, dass der Linux-Kernel-Stack 2014 für x86-Plattformen erweitert wurde, so dass dies möglicherweise kein Problem mehr darstellt.
Eine erste Version der „kcryptd_io“-Workqueue wurde 2007 mit der Absicht hinzugefügt, Folgendes zu vermeiden:
Starvation, verursacht durch viele Anfragen, die auf eine Speicherzuweisung warten…
Die Verarbeitung von Anfragen führte hier zu Engpässen in einer einzigen Workqueue, also war die Lösung, eine weitere hinzuzufügen. Macht Sinn.
Wir sind definitiv nicht die Ersten, die Leistungseinbußen aufgrund umfangreicher Warteschlangen erleben: 2011 wurde eine Änderung eingeführt, um einen Teil der Warteschlangen für Leseanfragen bedingt rückgängig zu machen:
Wenn genügend Speicher vorhanden ist, kann der Code Bio direkt übermitteln, anstatt diesen Vorgang in einem separaten Thread in die Warteschlange zu stellen.
Leider waren damals die Commit-Meldungen des Linux-Kernels nicht so ausführlich wie heute, so dass keine Leistungsdaten verfügbar sind.
Im Jahr 2015 begann dm-crypt, Schreibvorgänge in einem separaten „dmcrypt_write“-Thread zu sortieren, bevor sie den Stapel hinuntergeschickt wurden:
Auf einem Multiprozessor-Rechner werden Verschlüsselungsanforderungen in einer anderen Reihenfolge beendet als sie eingereicht wurden. Folglich würden die Schreibanforderungen in einer anderen Reihenfolge übermittelt werden, was zu einer erheblichen Leistungsverschlechterung führen könnte.
Das macht Sinn, da der sequentielle Plattenzugriff früher viel schneller war als der zufällige und dm-crypt dieses Muster durchbrochen hat. Aber das gilt vor allem für Spinning Disks, die 2015 noch dominant waren. Bei modernen schnellen SSDs (einschließlich NVME-SSDs) ist es vielleicht nicht so wichtig.
Ein weiterer Teil der Commit-Meldung ist erwähnenswert:
…insbesondere ermöglicht es IO-Schedulern wie CFQ, effektiver zu sortieren…
Er erwähnt die Leistungsvorteile für den CFQ-IO-Scheduler, aber Linux-Scheduler haben sich seitdem so weit verbessert, dass der CFQ-Scheduler 2018 aus dem Kernel entfernt wurde.
Das gleiche Patchset ersetzt die Sortierliste durch einen rot-schwarzen Baum:
In der Theorie sollte die Sortierung durch den zugrunde liegenden Festplatten-Scheduler durchgeführt werden, in der Praxis akzeptiert und sortiert der Festplatten-Scheduler jedoch nur eine endliche Anzahl von Anfragen. Um die Sortierung aller Anfragen zu ermöglichen, muss dm-crypt seine eigene Sortierung implementieren.
Der Overhead, der mit der rbtree-basierten Sortierung verbunden ist, wird als vernachlässigbar angesehen, so dass sie nicht bedingt verwendet wird.
All das macht Sinn, aber es wäre schön, einige Daten zur Unterstützung zu haben.
Interessanterweise sehen wir im selben Patchset die Einführung unserer bekannten „submit_from_crypt_cpus“-Option:
Es gibt einige Situationen, in denen das Auslagern von Schreibvorgängen von den Verschlüsselungs-Threads auf einen einzelnen Thread die Leistung erheblich verschlechtert
Insgesamt können wir sehen, dass jede Änderung sinnvoll und notwendig war, allerdings haben sich die Dinge seitdem geändert:
- Hardware wurde schneller und intelligenter
- Die Linux-Ressourcenzuweisung wurde überarbeitet
- gekoppelte Linux-Subsysteme wurden neu architektiert
Und viele der oben genannten Design-Entscheidungen sind möglicherweise nicht mehr auf modernes Linux anwendbar.
Die „Säuberung“
Auf der Grundlage der obigen Untersuchung haben wir beschlossen, all die zusätzlichen Warteschlangen und das asynchrone Verhalten zu entfernen und dm-crypt zu seinem ursprünglichen Zweck zurückzukehren: einfach IO-Anfragen zu ver- und entschlüsseln, während sie durchlaufen. Im Interesse der Stabilität und weiterer Benchmarking-Tests haben wir den eigentlichen Code jedoch nicht entfernt, sondern eine weitere dm-crypt-Option hinzugefügt, die alle Warteschlangen/Threads umgeht, wenn sie aktiviert ist. Das Flag ermöglicht es uns, zur Laufzeit unter voller Produktionslast zwischen dem aktuellen und dem neuen Verhalten zu wechseln, so dass wir unsere Änderungen leicht rückgängig machen können, sollten wir irgendwelche Nebenwirkungen feststellen. Der resultierende Patch kann auf dem Cloudflare GitHub Linux Repository gefunden werden.
Synchronous Linux Crypto API
Aus dem obigen Diagramm können wir uns erinnern, dass nicht alle Warteschlangen in dm-crypt implementiert sind. Die moderne Linux Crypto API kann auch asynchron sein, und für dieses Experiment wollen wir auch dort Warteschlangen eliminieren. Was bedeutet aber „möglicherweise“? Das Betriebssystem kann verschiedene Implementierungen desselben Algorithmus enthalten (z. B. hardwarebeschleunigtes AES-NI auf x86-Plattformen und generische C-Code-AES-Implementierungen). Standardmäßig wählt das System den „besten“ Algorithmus auf der Grundlage der konfigurierten Algorithmuspriorität aus. dm-crypt erlaubt es, dieses Verhalten außer Kraft zu setzen und eine bestimmte Verschlüsselungsimplementierung unter Verwendung des Präfixes capi: anzufordern. Dabei gibt es jedoch ein Problem. Schauen wir uns die verfügbaren AES-XTS-Implementierungen auf unserem System an:
$ grep -A 11 'xts(aes)' /proc/cryptoname : xts(aes)driver : xts(ecb(aes-generic))module : kernelpriority : 100refcnt : 7selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : cryptd(__xts-aes-aesni)module : cryptdpriority : 451refcnt : 1selftest : passedinternal : yestype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : xts(aes)driver : xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 1selftest : passedinternal : notype : skcipherasync : yesblocksize : 16min keysize : 32max keysize : 64--name : __xts(aes)driver : __xts-aes-aesnimodule : aesni_intelpriority : 401refcnt : 7selftest : passedinternal : yestype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64 Wir möchten explizit eine synchrone Chiffre aus der obigen Liste auswählen, um Warteschlangeneffekte in Threads zu vermeiden, aber die einzigen beiden unterstützten sind xts(ecb(aes-generic)) (die allgemeine C-Implementierung) und __xts-aes-aesni (die hardwarebeschleunigte x86-Implementierung). Wir wollen auf jeden Fall die letztere, da sie viel schneller ist (wir zielen hier auf Leistung ab), aber sie ist verdächtigerweise als intern gekennzeichnet (siehe internal: yes). Wenn wir uns den Quellcode ansehen:
Markiere eine Chiffre als Service-Implementierung, die nur von einer anderen Chiffre und niemals von einem normalen Benutzer der Kernel-Crypto-API verwendet werden kann
Diese Chiffre soll also nur von anderem Wrapper-Code in der Crypto-API und nicht außerhalb davon verwendet werden. In der Praxis bedeutet dies, dass der Aufrufer der Crypto API dieses Flag explizit angeben muss, wenn er eine bestimmte Cipher-Implementierung anfordert, aber dm-crypt tut dies nicht, da es vom Design her nicht Teil der Linux Crypto API ist, sondern ein „externer“ Benutzer. Wir haben das dm-crypt-Modul bereits gepatcht, also könnten wir auch einfach das entsprechende Flag hinzufügen. Es gibt jedoch noch ein weiteres Problem mit AES-NI im Besonderen: x86 FPU. „Fließkomma“ sagen Sie? Warum brauchen wir Fließkomma-Mathematik für symmetrische Verschlüsselung, bei der es nur um Bitverschiebungen und XOR-Operationen gehen sollte? Wir brauchen die Mathematik nicht, aber die AES-NI-Befehle verwenden einige der CPU-Register, die für die FPU bestimmt sind. Leider behält der Linux-Kernel diese Register aus Leistungsgründen nicht immer im Interrupt-Kontext bei (das Speichern/Wiederherstellen der FPU ist teuer). Aber dm-crypt kann Code im Interrupt-Kontext ausführen, so dass wir riskieren, einige andere Prozessdaten zu beschädigen, und wir kehren zu der Aussage „es wäre sehr unklug, die Entschlüsselung in einem Interrupt-Kontext durchzuführen“ im ursprünglichen Code zurück.
Unsere Lösung, um das oben genannte Problem zu lösen, bestand darin, ein weiteres, etwas „intelligenteres“ Crypto-API-Modul zu erstellen. Dieses Modul ist synchron und führt keine eigene Verschlüsselung durch, sondern ist nur ein „Router“ für Verschlüsselungsanfragen:
- wenn wir die FPU (und damit AES-NI) im aktuellen Ausführungskontext verwenden können, leiten wir die Verschlüsselungsanfrage einfach an die schnellere, „interne“
__xts-aes-aesniImplementierung weiter (und können sie hier verwenden, weil wir jetzt Teil der Crypto-API sind) - andernfalls leiten wir die Verschlüsselungsanforderung an die langsamere, generische C-basierte
xts(ecb(aes-generic))-Implementierung weiter
Das Ganze verwenden
Lassen Sie uns den Prozess durchgehen, wie man das Ganze verwendet. Der erste Schritt ist, die Patches zu nehmen und den Kernel neu zu kompilieren (oder nur dm-crypt und unsere xtsproxy Module zu kompilieren).
Als nächstes starten wir unsere IO-Workload in einem separaten Terminal, damit wir sicherstellen können, dass wir den Kernel zur Laufzeit unter Last neu konfigurieren können:
$ sudo fio --filename=/dev/mapper/encrypted-ram0 --readwrite=readwrite --bs=4k --direct=1 --loops=1000000 --name=cryptcrypt: (g=0): rw=rw, bs=4K-4K/4K-4K/4K-4K, ioengine=psync, iodepth=1fio-2.16Starting 1 process...Im Hauptterminal stellen Sie sicher, dass unser neues Crypto-API-Modul geladen und verfügbar ist:
$ sudo modprobe xtsproxy$ grep -A 11 'xtsproxy' /proc/cryptodriver : xts-aes-xtsproxymodule : xtsproxypriority : 0refcnt : 0selftest : passedinternal : notype : skcipherasync : noblocksize : 16min keysize : 32max keysize : 64ivsize : 16chunksize : 16Konfigurieren Sie die verschlüsselte Festplatte so, dass sie unser neu geladenes Modul verwendet und aktivieren Sie unser gepatchtes dm-crypt-Flag (wir müssen das Low-Level-Tool dmsetup verwenden, da cryptsetup offensichtlich nichts von unseren Änderungen weiß):
$ sudo dmsetup table encrypted-ram0 --showkeys | sed 's/aes-xts-plain64/capi:xts-aes-xtsproxy-plain64/' | sed 's/$/ 1 force_inline/' | sudo dmsetup reload encrypted-ram0Wir haben gerade die neue Konfiguration „geladen“, aber damit sie wirksam wird, müssen wir das verschlüsselte Gerät anhalten/fortsetzen:
$ sudo dmsetup suspend encrypted-ram0 && sudo dmsetup resume encrypted-ram0Und jetzt beobachten Sie das Ergebnis. Wir können zum anderen Terminal zurückkehren, auf dem der fio-Job ausgeführt wird, und uns die Ausgabe ansehen, aber um die Sache zu verschönern, hier ein Schnappschuss des beobachteten Lese-/Schreibdurchsatzes in Grafana:
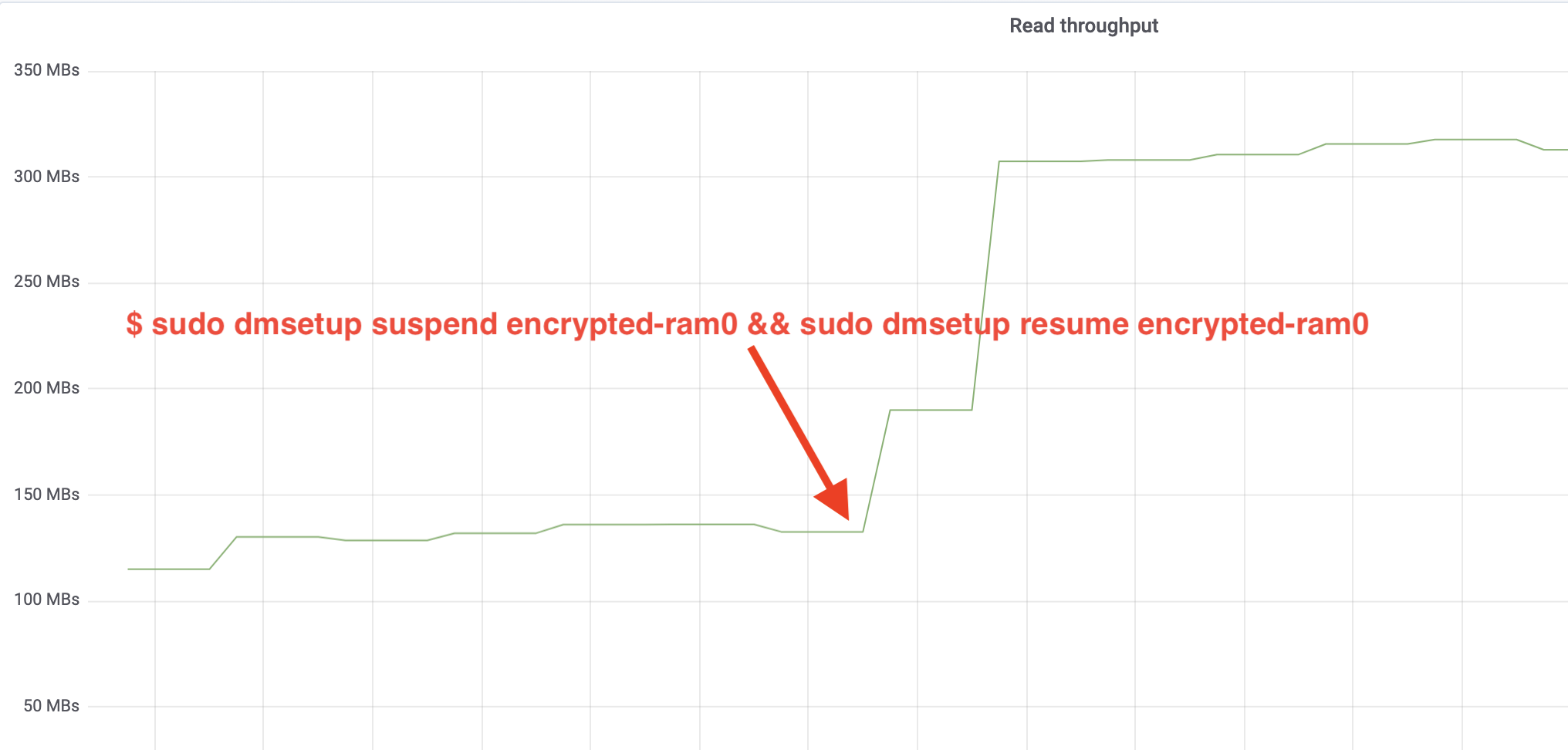
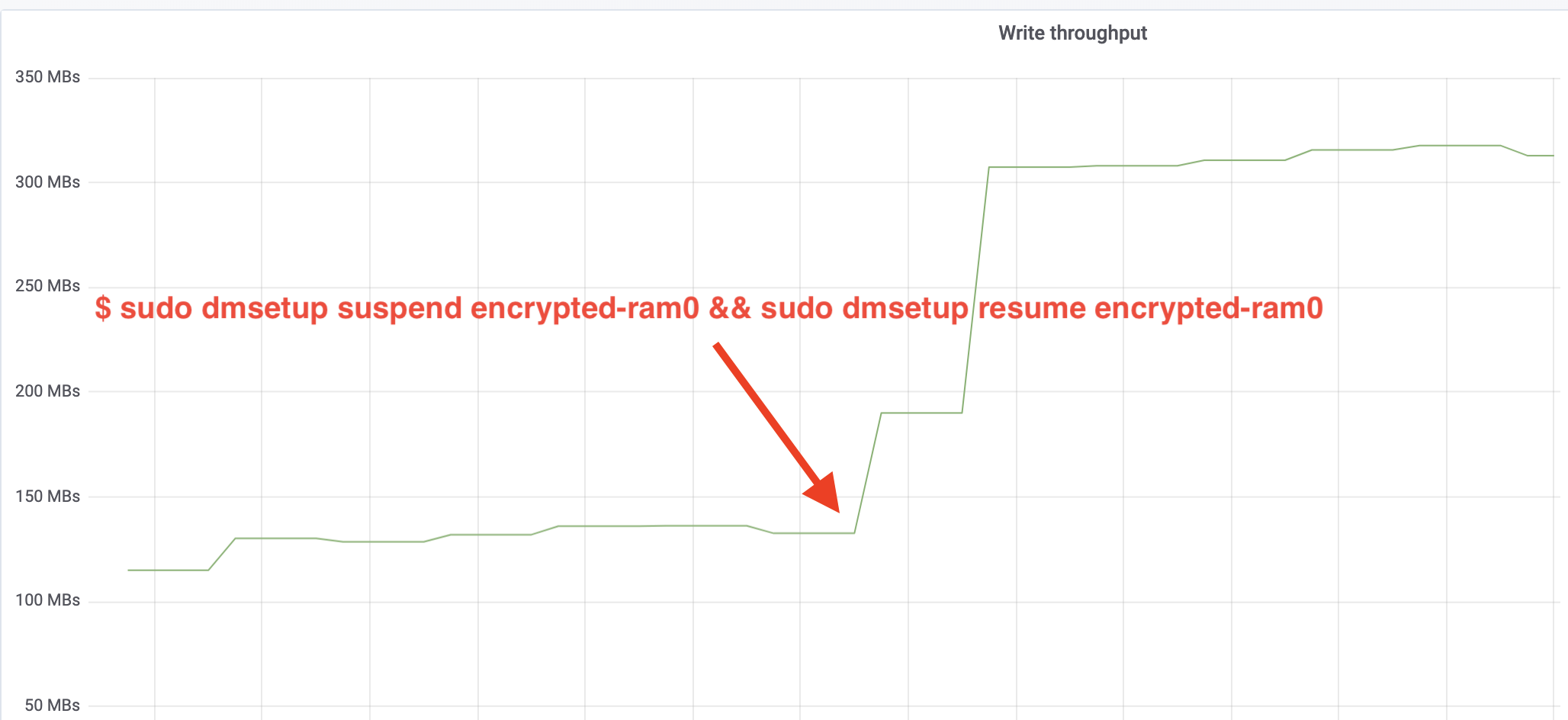
Wow, wir haben den Durchsatz mehr als verdoppelt! Mit dem Gesamtdurchsatz von ~640 MB/s sind wir jetzt viel näher an den erwarteten ~696 MB/s von oben. Wie sieht es mit der IO-Latenz aus? (Die await-Statistik aus dem iostat-Reporting-Tool):
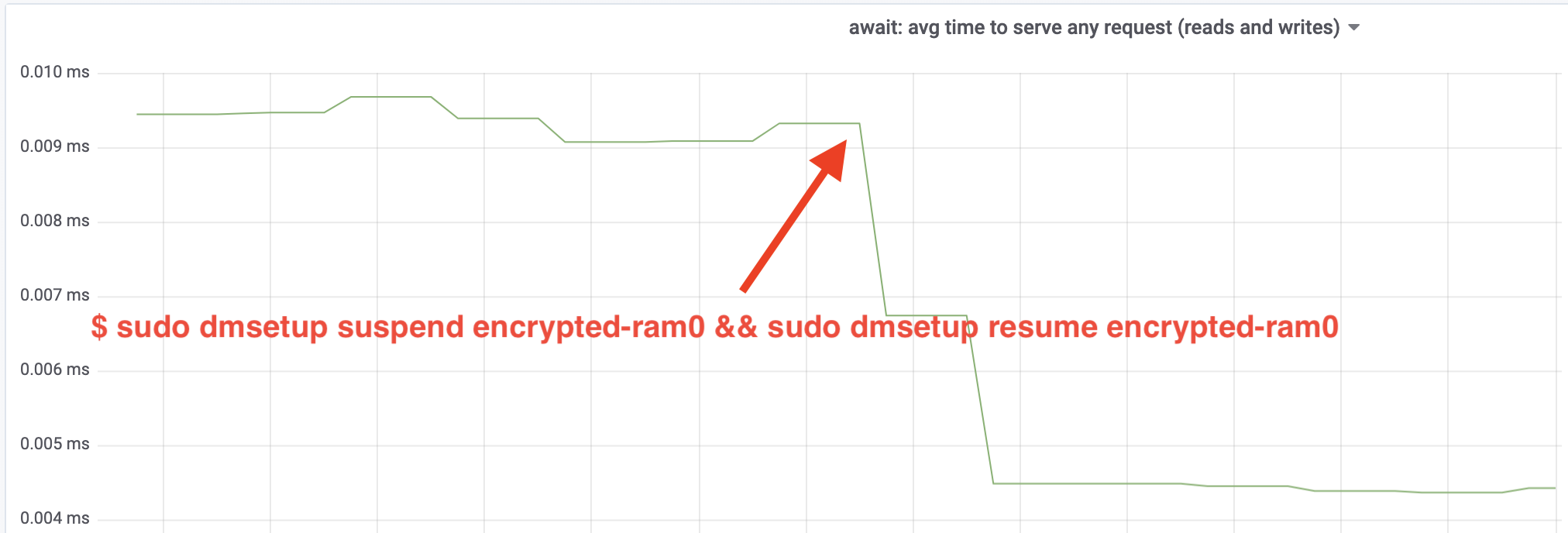
Die Latenz hat sich ebenfalls halbiert!
Zur Produktion
Bislang haben wir ein synthetisches Setup verwendet, bei dem einige Teile des vollständigen Produktions-Stacks fehlten, wie z. B. Dateisysteme, echte Hardware und vor allem die Produktionsauslastung. Um sicherzustellen, dass wir keine imaginären Dinge optimieren, hier eine Momentaufnahme der Auswirkungen dieser Änderungen auf den Cache-Teil unseres Stacks:

Dieses Diagramm stellt einen Drei-Wege-Vergleich der Worst-Case-Antwortzeiten (99. Perzentil) für einen Cache-Treffer auf einem unserer Server dar. Die grüne Linie stammt von einem Server mit unverschlüsselten Festplatten, den wir als Grundlinie verwenden werden. Die rote Linie stammt von einem Server mit verschlüsselten Festplatten mit der Standardimplementierung der Linux-Festplattenverschlüsselung und die blaue Linie von einem Server mit verschlüsselten Festplatten und aktivierten Optimierungen. Wie wir sehen können, hat die Standardimplementierung der Linux-Festplattenverschlüsselung in Worst-Case-Szenarien einen signifikanten Einfluss auf unsere Cache-Latenz, während die gepatchte Implementierung nicht von der Nichtverwendung der Verschlüsselung zu unterscheiden ist. Mit anderen Worten: Die verbesserte Verschlüsselungsimplementierung hat keinerlei Auswirkungen auf unsere Cache-Antwortgeschwindigkeit, wir bekommen sie also im Grunde genommen umsonst! Das ist ein Gewinn!
Wir haben gerade erst angefangen
Dieser Beitrag zeigt, wie eine Architekturüberprüfung die Leistung eines Systems verdoppeln kann. Außerdem haben wir erneut bestätigt, dass moderne Kryptographie nicht teuer ist und es in der Regel keine Ausrede gibt, seine Daten nicht zu schützen.
Wir werden diese Arbeit zur Aufnahme in den Hauptkernel-Quellbaum einreichen, aber höchstwahrscheinlich nicht in der aktuellen Form. Obwohl die Ergebnisse ermutigend aussehen, dürfen wir nicht vergessen, dass Linux ein hochgradig portables Betriebssystem ist: Es läuft sowohl auf leistungsstarken Servern als auch auf kleinen, ressourcenbeschränkten IoT-Geräten und auch auf vielen anderen CPU-Architekturen. Die aktuelle Version der Patches optimiert nur die Festplattenverschlüsselung für eine bestimmte Arbeitslast auf einer bestimmten Architektur, aber Linux braucht eine Lösung, die überall reibungslos läuft.
Wenn Sie also denken, dass Ihr Fall ähnlich ist und Sie die Leistungsverbesserungen jetzt nutzen wollen, können Sie die Patches holen und hoffentlich Feedback geben. Das Runtime-Flag macht es einfach, die Funktionalität während der Laufzeit umzuschalten, und ein einfacher A/B-Test kann durchgeführt werden, um zu sehen, ob es für einen bestimmten Fall oder ein bestimmtes Setup von Vorteil ist. Diese Patches wurden in unserem großen Netzwerk von mehr als 200 Rechenzentren auf fünf Hardware-Generationen ausgeführt und können daher als stabil angesehen werden. Genießen Sie sowohl die Leistung als auch die Sicherheit von Cloudflare für alle!

Update (11. Oktober 2020)
Der Hauptpatch aus diesem Blog (in leicht aktualisierter Form) wurde in den Mainline-Linux-Kernel integriert und ist ab Version 5.9 verfügbar. Der Hauptunterschied besteht darin, dass in der Mainline-Version zwei Flags statt einem gesetzt sind, die die Möglichkeit bieten, dm-crypt-Workqueues für Lese- und Schreibvorgänge unabhängig voneinander zu umgehen. Einzelheiten finden Sie in der offiziellen dm-crypt-Dokumentation.