Das Verständnis der Grundlagen des Schemamanagements ist entscheidend für den Aufbau und die Pflege einer effektiven PostgreSQL-Datenbank. In diesem Artikel werden wir uns die traditionelle Art und Weise der Verwaltung eines PostgreSQL-Schemas und eine neuere, effektivere Art und Weise ansehen, dies visuell zu tun, ohne eine Zeile Code schreiben zu müssen.
Was ist ein PostgreSQL-Schema?
Zunächst müssen wir einige Begriffe klären, um die Grundlage für diesen Artikel zu schaffen. In Postgres wird das Schema auch als Namespace bezeichnet. Der Namespace kann mit einem Familiennamen verbunden werden. Er wird verwendet, um bestimmte Objekte in der Datenbank (Tabellen, Ansichten, Spalten usw.) zu identifizieren und zu unterscheiden. Es ist nicht erlaubt, zwei Tabellen mit demselben Namen in einem Schema zu erstellen, aber Sie können dies in zwei verschiedenen Schemata tun. Zum Beispiel können wir zwei Tabellen mit dem Namen table1 sowohl im public als auch im postgres Schema haben.
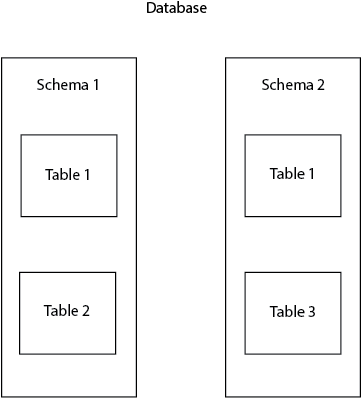
Warum Schemas verwenden?
Schemas sind sehr nützlich, um Datenbankobjekte in logischen Gruppen zu organisieren und Namenskollisionen zu vermeiden. Außerdem werden Schemata oft verwendet, um verschiedenen Benutzern die Arbeit mit der Datenbank zu ermöglichen, ohne sich gegenseitig zu behindern. Ein häufiges Beispiel ist, dass jeder Datenbankbenutzer an seinem eigenen Schema arbeitet, ohne andere Benutzer zu stören und Konflikte zu vermeiden.
Der klassische Weg, PostgreSQL Schemas zu verwalten
Alle folgenden Abfragen werden von der PostgreSQL Shell aus ausgeführt.
Erstellen eines Schemas
Wenn Sie eine neue Datenbank in Postgres erstellen, ist das Standardschema öffentlich. Ein neues Schema kann durch Ausführen der folgenden Abfrage erstellt werden:
CREATE SCHEMA schema_1;
vor dem Hinzufügen einiger Tabellen, werde ich zwei wichtige Konzepte erklären: Qualifizierte und unqualifizierte Namen.
-
Ein qualifizierter Name ist der Schemaname und der Tabellenname, getrennt durch einen Punkt. Damit wird das Schema angegeben, in dem wir unsere Tabelle erstellen wollen:
xxxxxxxxxx
CREATE TABLE schema_name.table_name (...);
-
Ein unqualifizierter Name besteht nur aus dem Tabellennamen. Dadurch wird die Tabelle in der ausgewählten Datenbank erstellt, die standardmäßig öffentlich ist. Dies kann über den search_path geändert werden, aber darauf gehen wir später noch genauer ein. Ein Beispiel für eine unqualifizierte Namensgebung ist:
xxxxxxxxxx
CREATE TABLE table_name (...);
Die Spalten der Tabellen werden innerhalb der Klammern aus den obigen Abfragen definiert (…).
Um eine neue Tabelle in unserem neuen Schema zu erstellen, werden wir ausführen:
xxxxxxxxxx
CREATE TABLE schema_1.persons (name text, age int);
Um das Schema fallen zu lassen, haben wir zwei Möglichkeiten. Wenn das Schema leer ist (keine Tabelle, Ansicht oder andere Objekte enthält), können wir ausführen:
xxxxxxxxxx
DROP SCHEMA schema_1;
Wenn das Schema Datenbankobjekte enthält, wird der Kaskadenbefehl eingefügt:
xxxxxxxxxx
DROP SCHEMA schema_1 CASCADE;
In PostgreSQL ist es auch möglich, ein Schema zu erstellen, das einem anderen Benutzer gehört mit:
xxxxxxxxxx
CREATE SCHEMA schema_name AUTHORIZATION username;
Suchpfad
Wenn ein Befehl mit einem unqualifizierten Namen ausgeführt wird, Postgres folgt einem Suchpfad, um zu bestimmen, welche Schemas verwendet werden sollen. Standardmäßig ist der Suchpfad auf das öffentliche Schema eingestellt. Um es anzuzeigen, führen Sie aus:
xxxxxxxxxx
SHOW search_path;
Wenn in Ihrer Datenbank nichts geändert wurde, sollte diese Abfrage das nächste Ergebnis liefern:
xxxxxxxxxx
search_path
--------------
"$user",public
Der Suchpfad kann so geändert werden, dass das System automatisch ein anderes Schema auswählt, wenn Sie einen nicht qualifizierten Namen verwenden. Das erste Schema im Suchpfad wird als aktuelles Schema bezeichnet. Ich werde zum Beispiel schema_1 als das aktuelle Schema festlegen:
xxxxxxxxxx
SET search_path TO schema_1,public;
Die nächste Abfrage wird einen unqualifizierten Namen verwenden, um eine Tabelle zu erstellen. Dadurch wird sie automatisch in schema_1 erstellt:
xxxxxxxxxx
CREATE TABLE address (city text, street text, number int);
Der neue Weg: Verwalten ohne Code!
Es gibt einen einfacheren Weg, alle Aufgaben der Schemaverwaltung zu erledigen, ohne eine Zeile Code schreiben zu müssen. Mit DbSchema können Sie alle oben genannten Abfragen von einer intuitiven Benutzeroberfläche aus mit nur wenigen Klicks ausführen. Das Verbinden mit der Datenbank dauert nur wenige Sekunden. Von Anfang an können Sie auswählen, mit welchem Schema Sie arbeiten möchten.
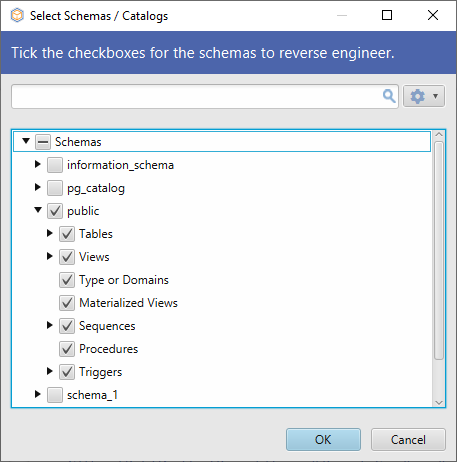
Das ausgewählte Schema oder die ausgewählten Schemata werden von DbSchema nachgebildet und im Layout angezeigt.
Um ein neues Schema zu erstellen, klicken Sie mit der rechten Maustaste auf den Schemaordner im linken Menü und wählen Sie Schema erstellen.
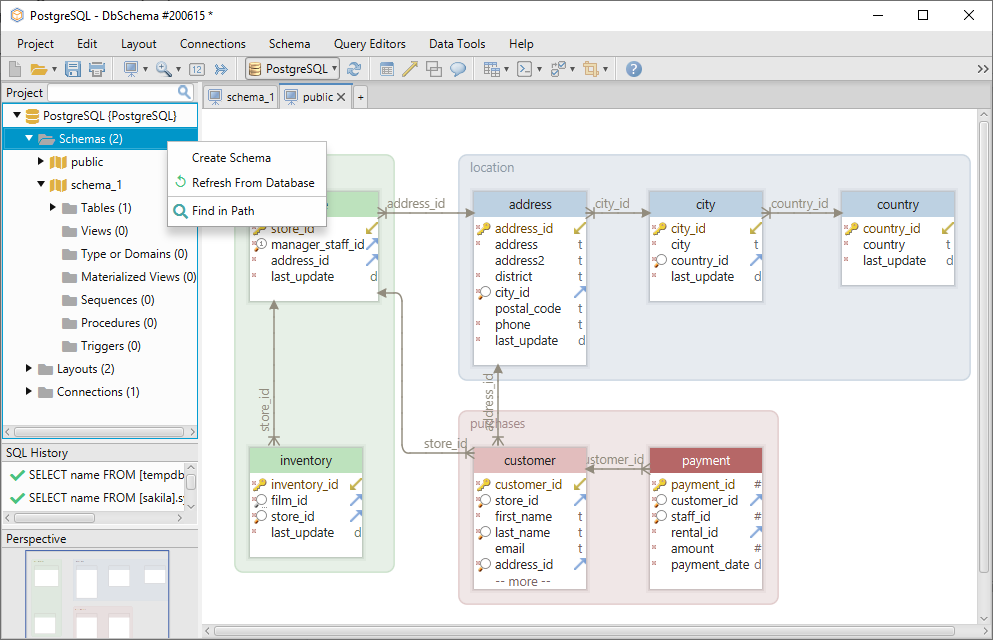
Um eine neue Tabelle im Schema zu erstellen, klicken Sie mit der rechten Maustaste auf das Layout und wählen Sie Tabelle erstellen.
Das Schema kann durch Rechtsklick auf seinen Namen aus dem linken Menü gelöscht werden.
Um ein anderes Schema aus der Datenbank hinzuzufügen, wählen Sie Aus Datenbank aktualisieren.
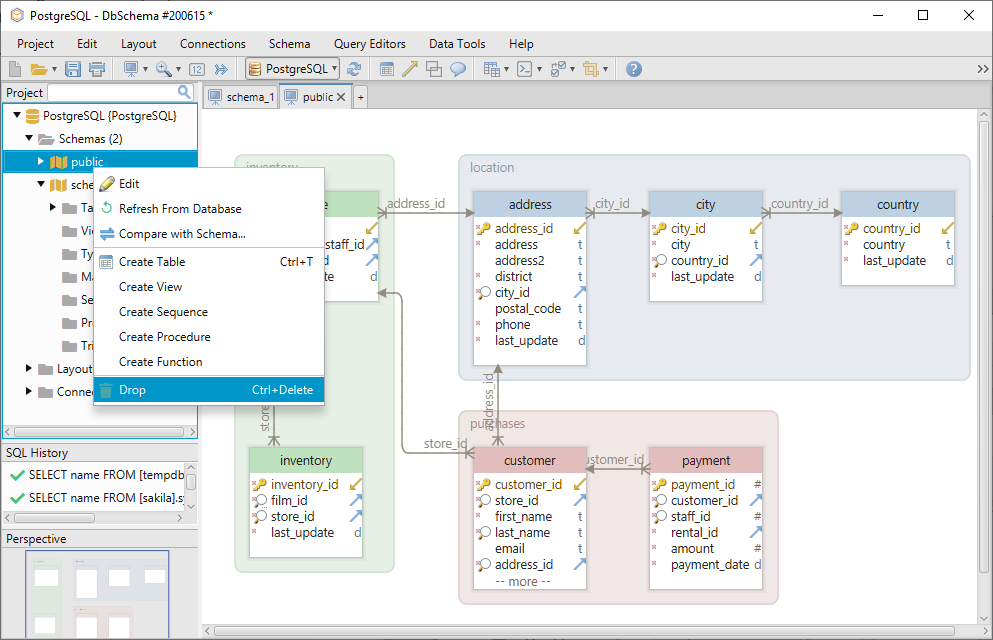
Bei der Verwendung von DbSchema müssen Sie die show_path-Syntax nicht verwenden, da Sie die Tabellen direkt im Layout erstellen können. Ein Layout kann mit einem Zeichenbrett verglichen werden, auf dem Sie die Tabellen hinzufügen und bearbeiten können. Jedem Layout ist ein Schema zugeordnet. Wenn Sie sich also im Layout schema_1 befinden, werden die Tabellen automatisch dort erstellt.
Offline arbeiten
DbSchema speichert ein lokales Abbild des Schemas in einer lokalen Projektdatei. Das bedeutet, dass die Projektdatei ohne Datenbankkonnektivität (offline) geöffnet werden kann. Im Offline-Modus können Sie alle oben beschriebenen Aktionen durchführen, allerdings ohne Daten. Nach Wiederherstellung der Verbindung zur Datenbank können Sie die Projektdatei mit der Datenbank vergleichen und entscheiden, welche Aktionen beibehalten oder verworfen werden sollen.
Das Gleiche kann zwischen zwei verschiedenen Versionen derselben Projektdatei gemacht werden. Wenn Sie zum Beispiel in einem Team arbeiten, kann es sein, dass es mehrere Schemata gibt (Produktion, Test, Entwicklung), von denen jedes seine eigene Projektdatei hat. Wenn eine Änderung in der Entwicklung auftaucht und Sie diese in den beiden anderen Schemata implementieren wollen, können Sie einfach die beiden Projektdateien vergleichen und synchronisieren.
Abschluss
Das Verständnis der oben aufgeführten Konzepte wird Ihnen helfen, Ihre PostgreSQL-Schemas einfach zu verwalten. Die Verwendung eines visuellen Designers wie DbSchema wird Ihre Arbeit noch einfacher machen, da Sie alles visuell erledigen können, ohne eine einzige Zeile Code schreiben zu müssen.